
1. Настройка нашего проекта
Table Of Content
Начнем с установки всех зависимостей, которые мы будем использовать для этого проекта. Предполагая, что у вас уже установлен Python 3, откройте VScode - или ваш редактор кода - и откройте новое окно терминала. Затем используйте следующие команды для установки библиотек:
- Requests:
pip3 install requests - Beautiful Soup:
pip3 install beautifulsoup4 - CSV: Python поставляется с готовым к использованию модулем CSV
После установки зависимостей давайте создадим новый файл и назовем его linkedin_python.py, а затем импортируем библиотеки в начале файла:
Теперь, когда наш файл готов к работе, давайте сначала изучим наш целевой веб-сайт. Перейдите на домашнюю страницу по адресу https://www.linkedin.com/ из окна браузера InPrivate (в режиме инкогнито в Chrome) и нажмите на jobs в верхней части страницы.
Это отправит нас непосредственно на страницу результатов поиска работы, где мы можем создать новый поиск. В данном примере предположим, что мы пытаемся составить список вакансий менеджера продукта в Сан-Франциско.
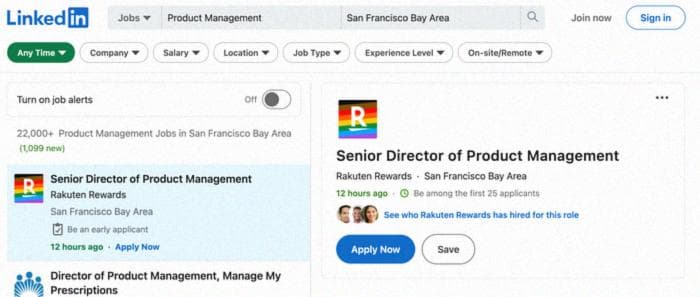
На первый взгляд, кажется, что каждая вакансия находится в контейнере, похожем на карточку, и, конечно же, после проверки страницы (щелкните правой кнопкой мыши > проверить), мы видим, что каждый результат работы находится между тегом <li> внутри элемента <ul>.
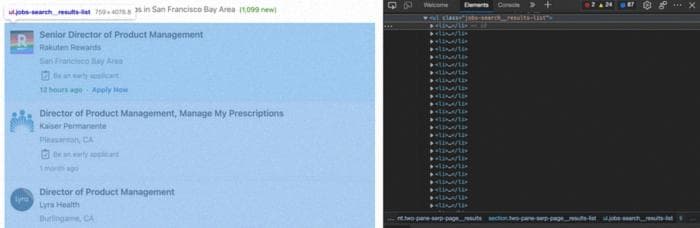
Таким образом, первым подходом будет получение элемента <ul> и перебор каждого тега <li> внутри него для извлечения нужных данных.
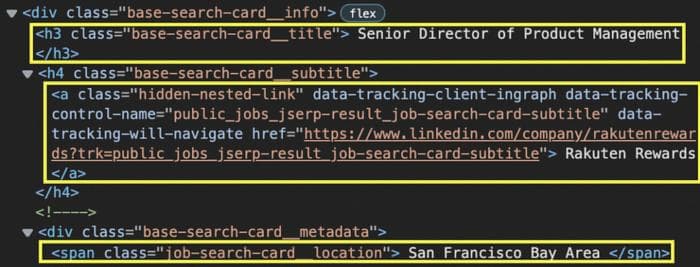
Но есть проблема: для доступа к новым вакансиям LinkedIn использует бесконечную прокрутку, что означает, что нет кнопки "следующая страница", чтобы получить ссылку на следующую страницу, и сам URL не меняется.
В таких случаях мы можем использовать безголовый браузер, такой как Selenium, чтобы получить доступ к сайту, извлечь данные, а затем прокрутить вниз, чтобы показать новые данные.
Конечно, как мы уже упоминали, мы этого не делаем. Вместо этого давайте обойдем сайт, используя вкладку Network в DevTools.