
Автоматическая генерация плейлистов YouTube из плейлистов Spotify с помощью JavaScript
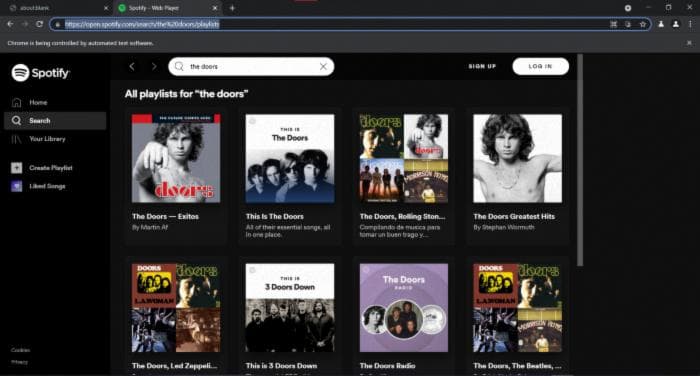
Table Of Content
- Создание веб-парсера с помощью JavaScript (Chrome + Puppeteer + Node.js)
- Перед началом
- Настройка проекта
- Кодирование
- Первые шаги
- Открываем браузер с помощью Puppeteer и выполняем первый поиск в Spotify.
- Получение найденных плейлистов и выбор первого.
- Восстановление треков плейлиста
- Создание плейлиста на YouTube
- GitHub - ljaviertovar/you-spoti: Парсер для получения песен из Spotify и создания плейлиста на YouTube
- В данный момент вы не можете выполнить это действие. Вы вошли в другую вкладку или окно. Вы вышли из системы в другой вкладке или окне...
- Парсинг: Что это такое и для чего оно используется?
- Что вам нужно знать, чтобы разработать свой первый парсер с использованием JavaScript
- Краткое руководство для начинающих в парсинге
Создание веб-парсера с помощью JavaScript (Chrome + Puppeteer + Node.js)

Если вы являетесь большим поклонником просмотра музыкальных видео, вам наверняка понравится возможность автоматического создания плейлистов на YouTube. Что ж, давайте попробуем что-то интересное.
Я любитель музыки, и все время слушаю свои любимые песни, но мне нравится не только слушать их, но и смотреть их видео. Однако у меня есть много плейлистов с множеством треков, и мне займет слишком много времени искать каждое видео по отдельности.
Было бы здорово, если бы мы могли экспортировать плейлист с какого-нибудь музыкального стримингового сайта, например, Spotify, и автоматически создать тот же плейлист, но с видео. Не так ли?
Итак, на этот раз мы разработаем веб-парсер, чтобы облегчить эту задачу.
Перед началом
Перед началом нам понадобится установить Node 8+ на наш компьютер. Вы можете узнать, как установить его здесь. Убедитесь, что выбираете версию "Current", так как она является 8+.
Настройка проекта
Начните с создания директории проекта
$ mkdir you-spoti
$ cd you-spotiИнициализируйте NPM. И введите необходимые детали.
$ npm initУстановите Puppeteer. Вы можете узнать, как начать здесь. Если вы хотите воспользоваться последней функциональностью, вы можете установить его напрямую из его репозитория на GitHub.
$ npm i --save puppeteerPuppeteer включает собственную версию Chrome/Chromium, которая гарантированно работает в режиме headless. Так что каждый раз, когда вы устанавливаете или обновляете Puppeteer, он будет загружать свою специфическую версию Chrome.
Установите urlencode. Этот пакет поможет нам закодировать URL-адреса, которые наш парсер должен посетить.
$ npm i urlencodeНаконец, откройте папку в вашем любимом редакторе кода и создайте файл index.js.
Кодирование
Первые шаги
Мы начнем с определения URL-адресов, которые будет посещать наш веб-парсер.
- https://open.spotify.com/ — URL-адрес веб-плеера Spotify
- https://www.youtube.com/ — Основной URL-адрес YouTube
Если мы просмотрим веб-сайт Spotify, мы увидим, что у этого сайта дружественные URL-адреса, что упрощает нашу работу.
Обычно нам приходится вводить текст для поиска и нажимать кнопку поиска, чтобы сайт перенаправил нас на следующую страницу с результатами, но мы можем сэкономить эти шаги и использовать только следующие URI.
https://open.spotify.com/search/{{текст для поиска}}https://open.spotify.com/playlist/76wniFNIRnxCXGXIvV5JUw {{название плейлиста}}
Открываем браузер с помощью Puppeteer и выполняем первый поиск в Spotify.
Как мы можем видеть в следующем коде, в моем случае я хочу искать плейлисты артиста "The Doors", поэтому я введу этот текст. Мы видим, что я уже конкатенирую закодированный текст с помощью urlencode, чтобы избежать проблем с URL-адресами Spotify.
По умолчанию Puppeteer работает в режиме headless, что означает, что мы не видим браузер. Мы хотим его увидеть, поэтому устанавливаем это свойство в false.
Если мы выполним наш парсер до этого момента, мы останемся на этом экране.
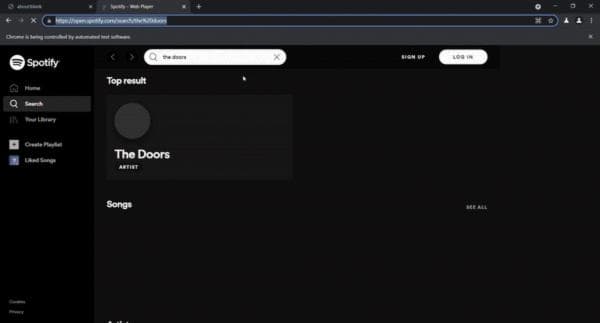
$ node index.jsПолучение найденных плейлистов и выбор первого.
В этой части мы ищем раздел плейлистов, затем нажимаем на первый плейлист.
Для этого мы используем функцию page.evaluate. Эта функция используется для входа в DOM данной страницы и доступа к нему, как если бы мы находились в консоли браузера.
Код внутри page.evaluate выполняется внутри браузера Chrome, поэтому переменные, объявленные за пределами этой функции в скрипте, не доступны браузеру, если мы не передадим их в качестве аргументов.
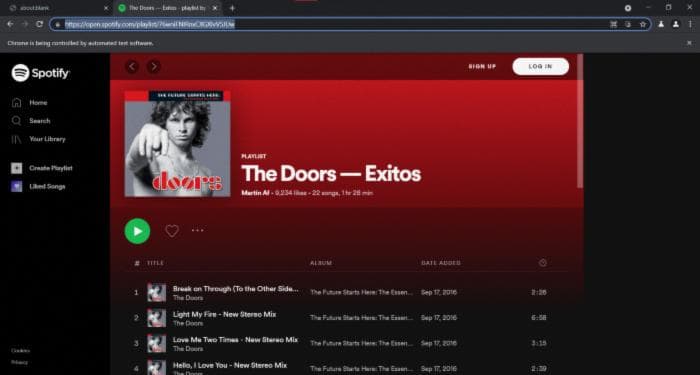
Теперь мы находимся на этом экране, внутри выбранного плейлиста.
Восстановление треков плейлиста
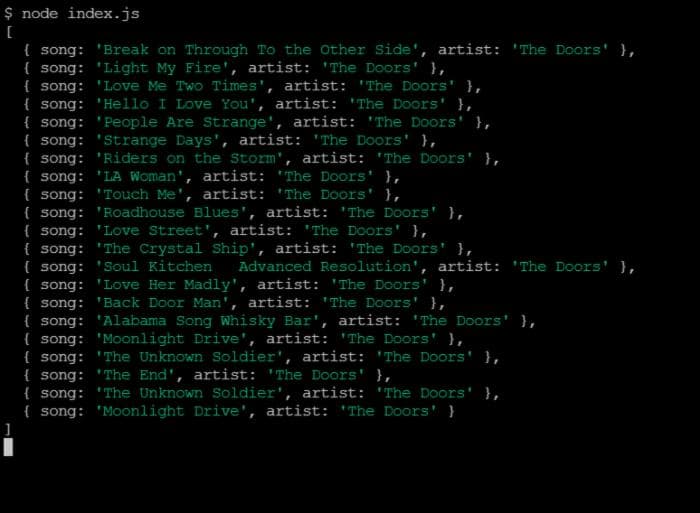
Теперь мы хотим извлечь все треки, содержащиеся в плейлисте. Для этого мы получаем все дочерние элементы родительского селектора и для каждого дочернего элемента извлекаем текст и очищаем его от странных символов.
Таким образом, у нас будет объект со всеми треками в плейлисте.
Создание плейлиста на YouTube
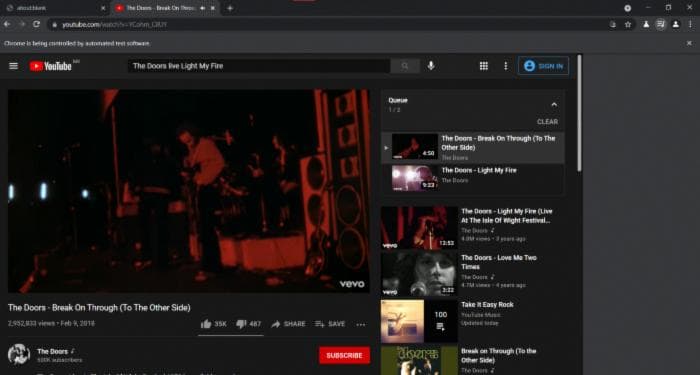
Наконец, мы переходим на YouTube и ищем по одному каждый трек. В цикле for of мы вводим название трека для поиска. В моем случае, я добавил текст "live", чтобы искать видео в прямом эфире, и нажимаем на значок поиска.
Чтобы добавить трек в плейлист, мы должны навести курсор на строку, где находится видео, чтобы появилась кнопка добавления в DOM, и мы можем нажать на нее.
Если мы посмотрим на эту часть, мы добавляем задержки, потому что часто Puppeteer работает быстрее, чем посещаемый нами веб-сайт, и мы не даем время для появления в DOM всех элементов, которые нам нужны.
Вот и все!
Если мы запустим скрипт, мы увидим волшебство! Мы видим, как каждый трек добавляется в список. После завершения работы у нас будет наш плейлист Spotify на YouTube.
Репозиторий проекта:
GitHub - ljaviertovar/you-spoti: Парсер для получения песен из Spotify и создания плейлиста на YouTube
В данный момент вы не можете выполнить это действие. Вы вошли в другую вкладку или окно. Вы вышли из системы в другой вкладке или окне...
github.com
Если вам все еще не ясно, как работает парсинг, вы можете посетить мою предыдущую статью.
Парсинг: Что это такое и для чего оно используется?
medium.com
Что вам нужно знать, чтобы разработать свой первый парсер с использованием JavaScript
Краткое руководство для начинающих в парсинге
medium.com
Помните, что перед парсингом необходимо учитывать условия использования и политику конфиденциальности веб-сайтов. Будьте ответственными за это.
**Хотите подключиться?**Люблю общаться с друзьями со всего мира в [Twitter](https://twitter.com/ljaviertovar)Больше контента на PlainEnglish.io. Подпишитесь на нашу бесплатную еженедельную рассылку. Подписывайтесь на нас в Twitter, LinkedIn, YouTube и Discord. Интересуетесь Growth Hacking? Посмотрите Circuit._