
Как ежедневно собирать данные с сайта в облаке с помощью Selenium от А до Я? (Часть 3/4)
Предыдущая часть: https://medium.com/@hureauxarnaud/comment-scraper-un-site-quotidiennement-en-cloud-avec-selenium-from-a-to-z-partie-2-4-19104a48538
3.1) Бонус 1: экспорт в Google Drive:
Создайте Google Sheet в своем диске.
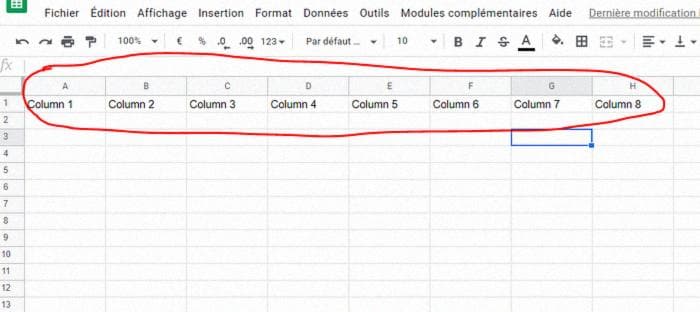
Добавьте 8 названий столбцов в свой набор данных (если вы изменили функцию Python и экспортируете фрейм данных с X столбцами, добавьте не 8, а X названий столбцов).
Перейдите на https://console.cloud.google.com
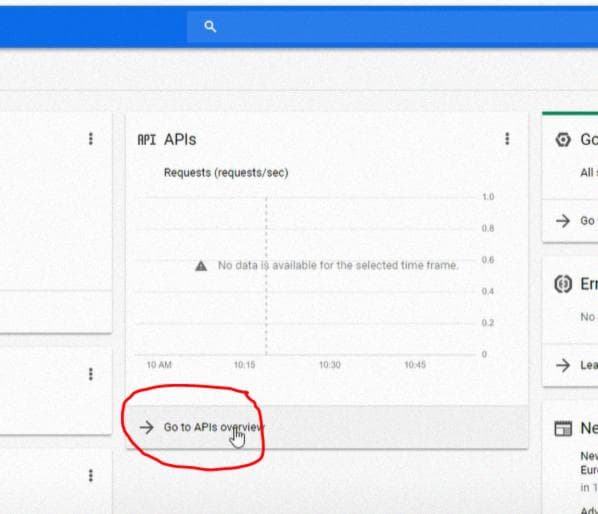
Перейдите в "API Overview", как показано на изображении ниже:
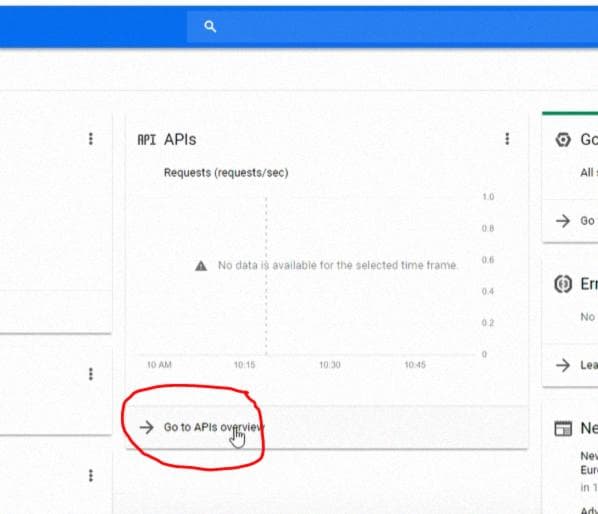
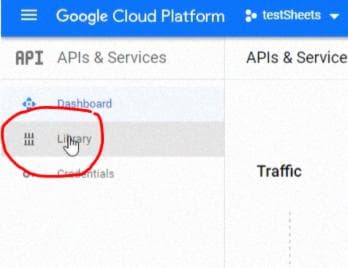
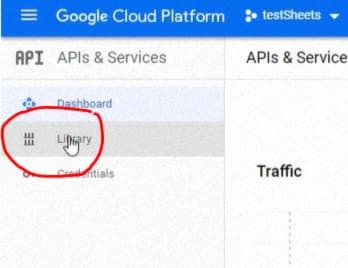
Затем перейдите в "Library":
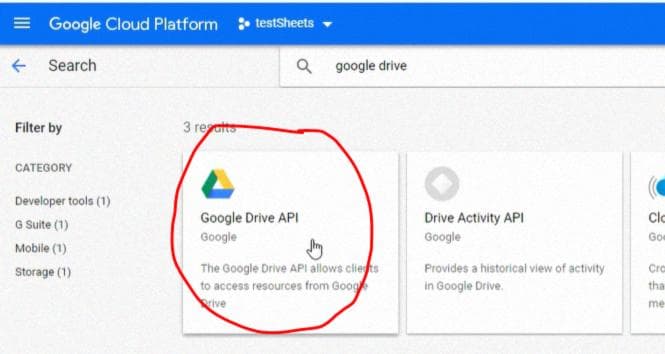
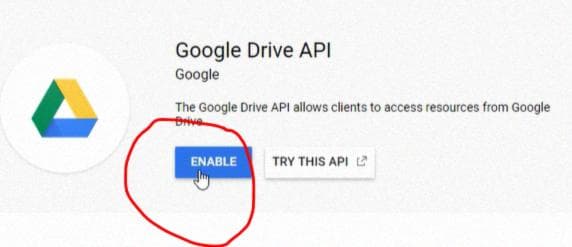
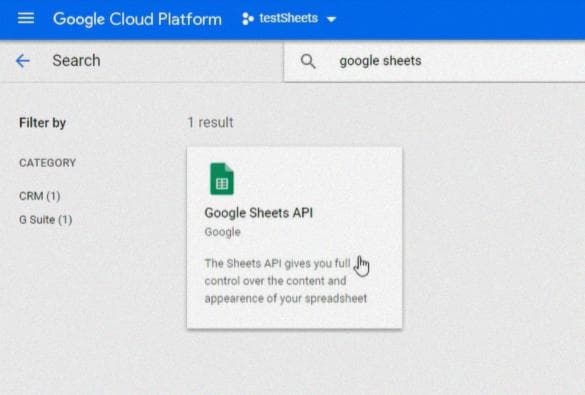
Затем выберите API Google Drive и активируйте его:
Теперь нажмите "Создать учетные данные" (кнопка должна появиться сразу после активации API Google Drive):
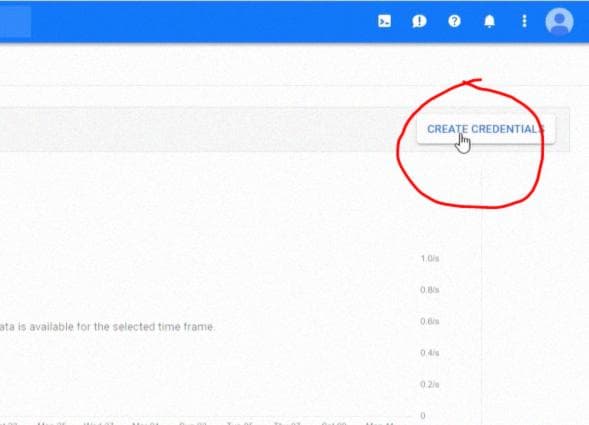
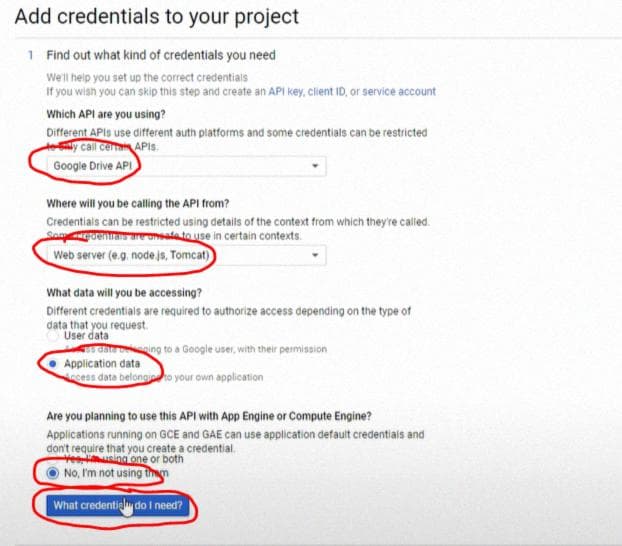
Настройте свои "credentials" следующим образом:
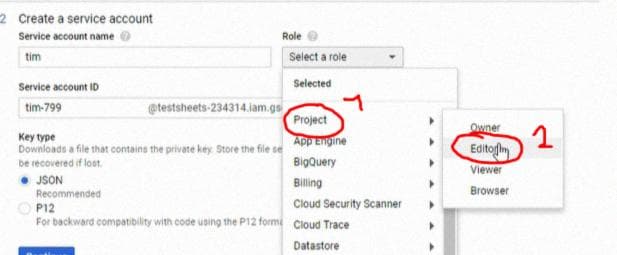
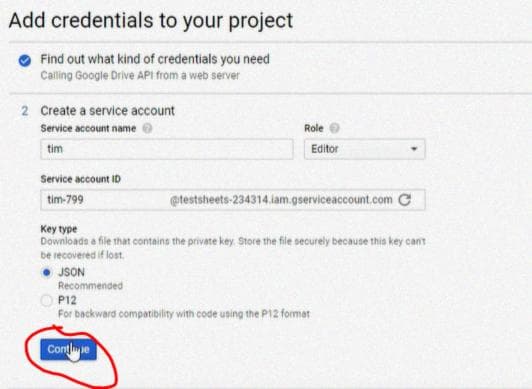
Это загрузит файл .json.
После загрузки вы можете активировать API Google Sheet (точно так же, как и для API Google Drive).
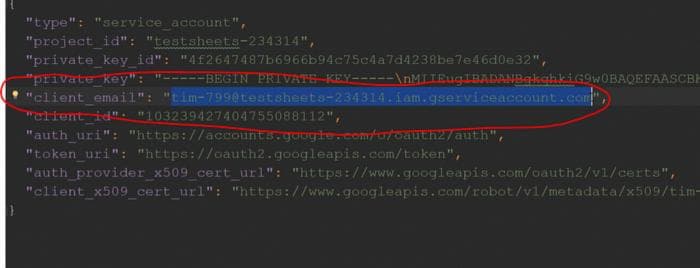
Теперь откройте загруженный файл .json с помощью блокнота (текстового редактора) и скопируйте странное электронное письмо, которое появляется на строке "client_email", без кавычек, как показано на изображении ниже:
Перейдите на Google Sheet, в которую вы хотите отправить свои данные, затем перейдите в "Поделиться":
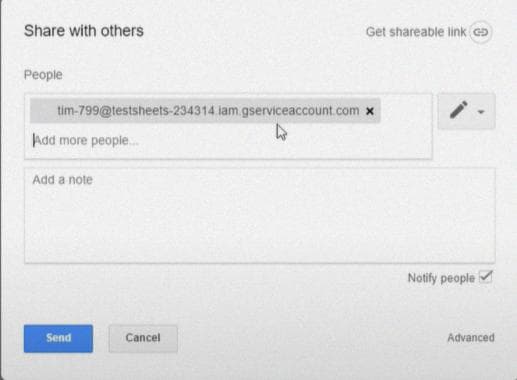
Добавьте странное электронное письмо из .json в список людей, с которыми вы делитесь файлом (давая полные права).
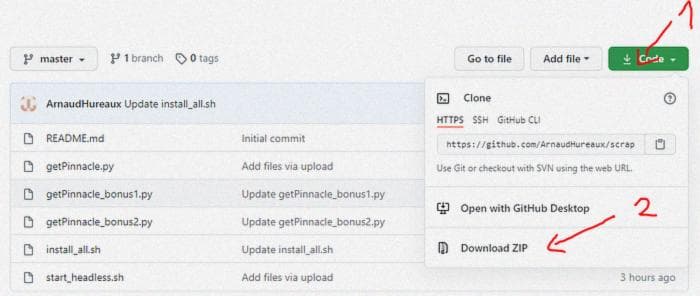
Загрузите файл getPinnacle_bonus1.py с GitHub (не загружайте его напрямую с помощью wget, так как вам нужно будет его изменить!) :
ArnaudHureaux/scraping-with-google-cloud
Внести вклад в развитие ArnaudHureaux/scraping-with-google-cloud, создав учетную запись на GitHub.
github.com
Это тот же файл, что и getPinnacle.py, за исключением того, что эти строки кода добавлены в конец файла, я выделил элементы, которые нужно изменить жирным шрифтом:
|import gspread
import pandas as pd
from oauth2client.service_account import ServiceAccountCredentialsdef updateGSwithDF(df,nameSheet): scope=['https://www.googleapis.com/auth/spreadsheets',
'https://www.googleapis.com/auth/drive.file',
'https://www.googleapis.com/auth/drive']creds=ServiceAccountCredentials.from_json_keyfile_name('**YourProject.json**',scope) client=gspread.authorize(creds) sh=client.open_by_url('**https://docs.google.com/spreadsheets/d/1Hz_DysSzKu_5f7Z7PngBtpK14Cpwm0cIq8w_O53bIkY/edit#gid=0**') sh=sh.worksheet(nameSheet)
a=sh.get_all_values() alphabet='ABCDEFGHIJKLMNOPQRSTUVWXYZ'
target='A'+str(len(a)+1)+':'+alphabet[len(a[0])-1]+str(len(a)+1+len(df)-1)
sh.update(target,df.values.tolist())
pi=getPinnacleDF()
pi.to_csv('pi.csv',index=False,header=True) pi = pi.applymap(str)
updateGSwithDF(pi,'**Feuille 1**')Чтобы это работало с вами, вам нужно изменить три вещи в файле Python "getPinnacleBonus1":
-
Вам нужно заменить имя .json "MyProject.json" на то, которое вы загрузили.
-
Вам нужно заменить имя вкладки, здесь "Feuille 1", на имя вашей вкладки. По умолчанию это "Sheet 1" на английском и "Feuille 1" на французском.
После внесения изменений вы можете импортировать getPinnacle_bonus1.py на сервер GCloud вместе с загруженным .json! (см. следующий скриншот)

Теперь установите необходимые библиотеки с помощью следующих команд:
|pip3 install gspread
pip3 install oauth2clientГотово, вы можете выполнить свой скрипт getPinnacle_bonus1.py с помощью команды:
|python3 getPinnacle_bonus1.pyТеперь посмотрите на свою таблицу Google, если файл был обновлен, значит все работает! Поздравляю!
getPinnacle_bonus1.py будет делать то же самое, что и getPinnacle.py, и отправит вам фрейм данных в вашу таблицу Google Sheet ;)
Имейте в виду, что функция updateGSwithDF работает независимо от количества столбцов в вашем фрейме данных, вам просто нужно указать количество имен столбцов, соответствующее количеству столбцов в вашем фрейме данных.
Не забудьте добавить строку "00 08 ***** ***** ***** python3 getPinnacle.py" в свой файл crontab, если вы хотите, чтобы парсинг запускался регулярно (обратите внимание, что экспорт не удалит предыдущие экспорты, а просто добавит новые).
Теперь вы можете либо перейти к следующей части, чтобы быть автоматически уведомленным по электронной почте при каждом экспорте (это удобно, чтобы убедиться, что нет ошибок), либо перейти непосредственно к части 4/4, где будет объяснен весь код.
3.2) Бонус 2: получение уведомления по электронной почте при каждом экспорте
Загрузите файл getPinnacle_bonus2.py с GitHub:
https://github.com/ArnaudHureaux/scraping-with-google-cloud
Это тот же файл, что и getPinnacle_bonus2.py, за исключением того, что эти строки кода добавлены в конец файла:
|def SendEmail():
user = 'yourmail@gmail.com'
app_password = 'your_app_password'
to = 'yourmail@gmail.com'
subject = 'Scraping : Pinnacle'
content = ['The site has been scrape sucessfully !']
with yagmail.SMTP(user, app_password) as yag:
yag.send(to, subject, content)
print('Sent email successfully.')Чтобы это работало, вам нужно ввести свой адрес электронной почты и сгенерированный вами app_password, следуя инструкциям в этом кратком и хорошо объясненном учебнике:
https://towardsdatascience.com/automate-sending-emails-with-gmail-in-python-449cc0c3c317
Спасибо, что следовали этому учебнику, вы можете перейти к последней части этого учебника, чтобы получить объяснение кода, ссылка на часть 4/4: https://medium.com/@hureauxarnaud/comment-scraper-un-site-quotidiennement-en-cloud-avec-selenium-from-a-to-z-partie-4-4-38c02f4dc040
Не стесняйтесь связаться со мной в LinkedIn, чтобы задать вопросы / познакомиться: www.linkedin.com/in/arnaud-hureaux-895421159
Спасибо!