
Как извлечь результаты из Google с помощью IMPORTFROMWEB: Парсинг с помощью Google Sheets
Парсинг данных - это передовая техника, которая позволяет извлекать данные с любого веб-сайта. Его использование бесконечно: анализ конкуренции, SEO-позиционирование, создание контента, отслеживание влиятелей, обнаружение ошибок на нашем сайте и т.д.
Однако выполнение парсинга данных обычно является затратной задачей, поскольку может потребоваться большое количество ресурсов, в зависимости от размера сайта, который мы хотим спарсить.
В мире SEO интересно проводить парсинг результатов Google. Это имеет несколько применений:
- Узнать позицию вашего веб-сайта для определенных ключевых слов
- Понять эволюцию позиционирования наших конкурентов
- Анализировать контент, который лучше всего позиционируется
Что если я скажу вам, что это можно сделать с помощью простой функции Google Sheets? Для этого нам просто нужно установить расширение Google Sheets IMPORTFROMWEB и следовать инструкциям в этой статье.
Как создавать запросы в Google
URL
Базовый синтаксис запроса в Google имеет следующие 3 параметра:
- q = слова, объединенные знаком +
- hl = язык результатов, в данном случае испанский
- num = 100, количество результатов, которые нужно показать, по умолчанию 10
И вот наш URL для выполнения запроса:
https://www.google.com/search?q=probando+google&hl=es&num=100
Путь элемента XPath
После получения URL нам понадобится путь XPath элементов, которые мы хотим спарсить. Для этого нам понадобятся базовые знания HTML.
XPath - это язык, используемый для описания элемента XML-сценария. Поскольку HTML производный от XML, мы также можем выполнять запросы XPath к веб-странице.
Простой пример: //h1 указывает на все заголовки страницы. Двойной слэш в начале указывает, что путь относительный, и элемент не обязательно является дочерним элементом корневого документа.
В нашем случае XPath будет немного сложнее:
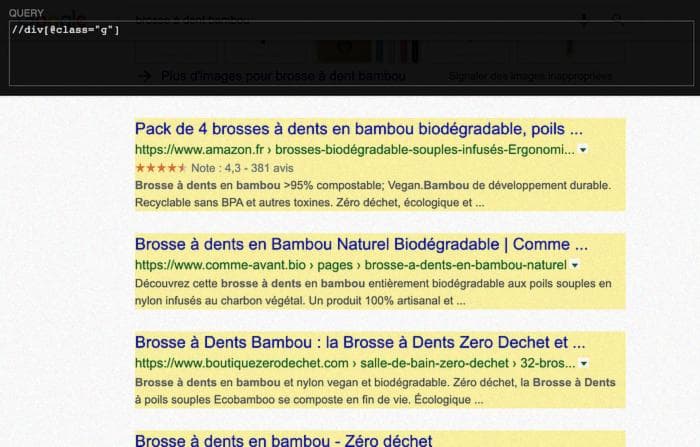
// div [@ class = “g”] // h3
Вы можете использовать расширение Chrome XPath Helper для создания своих собственных запросов. В этой статье вы можете узнать больше о возможностях XPath.
// div [@ class = “g”] указывает на все контейнеры для каждого результата. То есть все элементы класса "div" "g".
С помощью XPath Helper:
Добавив //h3, мы берем только заголовок каждого контейнера.
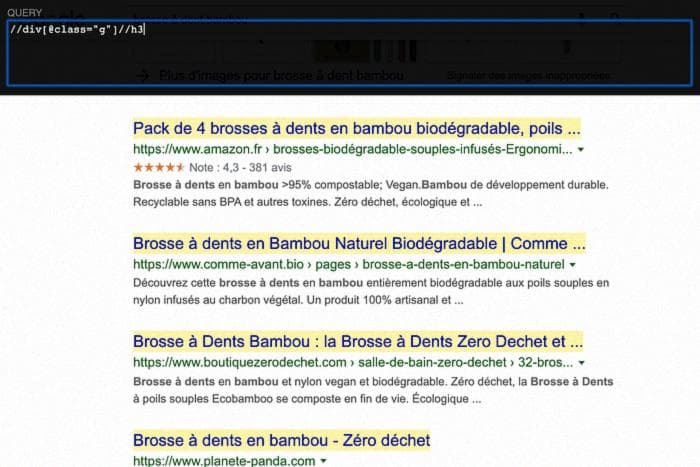
С помощью этого и функции IMPORTFROMWEB вы можете выполнять продвинутый парсинг данных, позволяющий извлекать заголовки страниц, которые находятся в топе Google для любого запроса. Вы видите потенциал этого, верно?
Google не всегда облегчает парсинг данных. Движок, на котором работает IMPORTFROMWEB, попытается загрузить страницу за 20 секунд, но в некоторых случаях может потребоваться больше времени. Если вы видите сообщение #PENDING_REQUESTS, откройте боковую панель плагинов: Плагины> IMPORTFROMWEB> Открыть боковую панель, а затем на вкладке Монитор нажмите Обновить ожидающие запросы
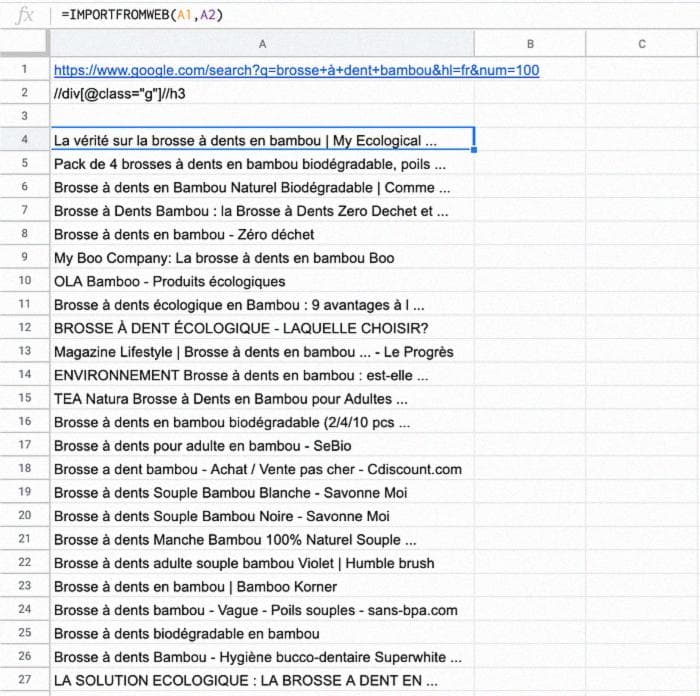
Вы должны увидеть что-то вроде этого:
Улучшение нашего парсера: добавление описания и ссылки
IMPORTFROMWEB имеет особенность принимать диапазон ячеек вместо селектора, что позволяет возвращать больше информации о результатах нашего поиска.
Используя предыдущую формулу:
Парсинг нескольких URL-адресов
Первый параметр функции IMPORTFROMWEB принимает массив значений, поэтому мы можем передать набор URL-адресов для обработки сразу. Это очень мощно, если мы комбинируем его с другими инструментами, такими как Screaming Frog, или если используем фильтр, такой как "site:", чтобы отфильтровать результаты нашего веб-сайта.