
Как: Парсинг и создание облака слов
Парсинг, создание собственного облака слов, веселье!! - "Серия инструкций"

Облако слов - это визуализация частоты слов в заданном тексте. Некоторые слова выглядят больше других, когда их частота встречаемости выше. Облака слов могут быть не подходящим методом визуализации в контексте важности слов в заданном тексте.
Здесь давайте посмотрим, как создать облако слов из данных, полученных из веб-сайта с помощью Python.
Шаг 1 - это парсинг, а шаг 2 - создание облака слов.
Сначала давайте получим текст, который нам нужен для создания облака слов. Здесь мы собираемся создать облако слов по алгоритмам и структурам данных. Мы возьмем список этих слов из википедии: https://en.wikipedia.org/wiki/List_of_terms_relating_to_algorithms_and_data_structures
1. Парсинг:
Нам нужно установить пакет BeautifulSoup для разбора HTML-документа.
pip install beautifulsoup4Импортируем необходимые пакеты
from bs4 import BeautifulSoup
import urllib"urllib" используется для открытия URL и получения информации из интернета.
url ="[https://en.wikipedia.org/wiki/List_of_terms_relating_to_algorithms_and_data_structures](https://en.wikipedia.org/wiki/List_of_terms_relating_to_algorithms_and_data_structures)"headers = {'user-agent':'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.3'}"headers" - необязательные параметры, но некоторые сайты не позволят вам получить доступ, если у вас нет правильных заголовков. Подробнее о заголовках и их синтаксисе можно прочитать здесь.
req = urllib.request.Request(url, headers=headers)
data = urllib.request.urlopen(req).read()"urllib.request.Request" - это класс, который представляет собой абстракцию запроса URL, где операции могут быть выполнены перед фактическим запросом.
soup= BeautifulSoup(data, "html.parser")Прочитанные данные, то есть HTML-содержимое, теперь разбираются с помощью BeautifulSoup.
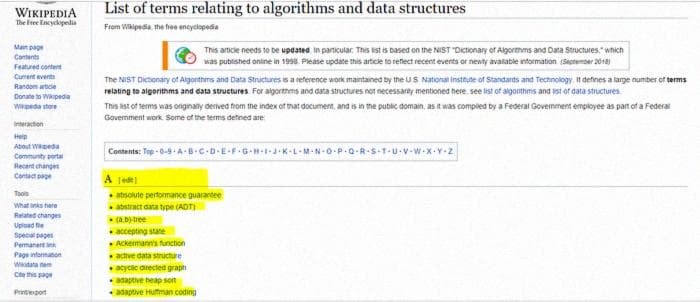
Теперь давайте посмотрим на веб-сайт, который мы хотим спарсить.
То, что нам нужно извлечь, это выделенное и другой список алгоритмов. Нам нужно взглянуть на HTML-код, чтобы определить "div", в котором он содержится, осмотрев элемент.
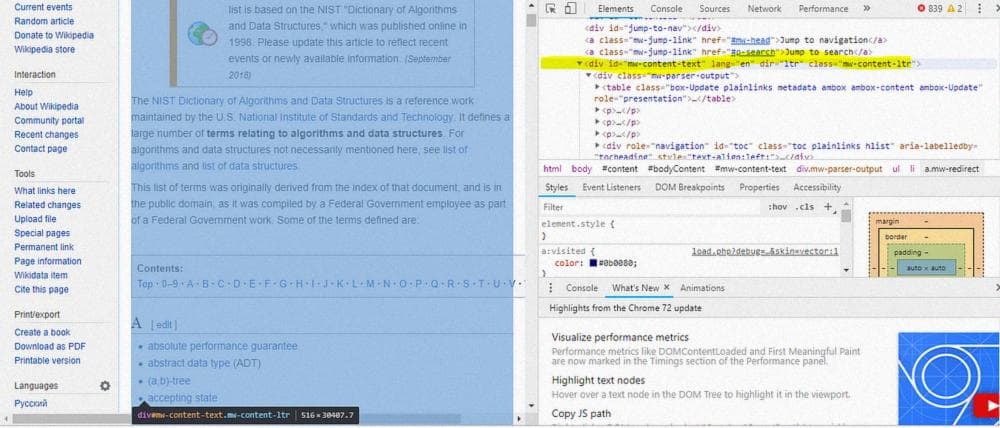
Информация содержится в выделенном "div".
main_content= soup.find("div", attrs= {"id" : "mw-content-text"})Все слова, которые нам нужны, представлены в виде маркированного списка. Поэтому достаточно получить данные, содержащиеся в теге <li>, чтобы получить их, как показано ниже.

lists = main_content.find_all("li")Теперь у нас есть данные, содержащиеся в теге <li>, в виде списка.
Но для создания облака слов нам нужны данные в виде строки.
str = ""
for list in lists:
info= list.text
str+=info2. Создание облака слов
Установим пакет WordCloud
pip install wordcloudSTOPWORDS - это слова, которые не должны появляться в облаке слов. Модуль Wordcloud содержит список предопределенных STOPWORDS, таких как "is", "are", "the" и т. д., которые часто встречаются в тексте, но не являются значимыми для обработки текста.
from wordcloud import WordCloud, STOPWORDS, ImageColorGenerator
import numpy as np
from PIL import Image
import matplotlib.pyplot as pltМы можем добавить слова в существующий список STOPWORDS
STOPWORDS.update(["see","common"])Облака слов могут быть созданы в любой форме. Отображение формы изображения на облако слов называется маскировкой. Для этого нам нужно преобразовать изображение в массив numpy.
mask = np.array(Image.open("Desktop/big.png"))Мы также можем отобразить тот же цвет, что и у изображения, на облаке слов. Для этого мы используем ImageColorGenerator.
color= ImageColorGenerator(mask)Мы передаем "mask" в качестве одного из параметров для создания облака слов. max-words указывает максимальное количество слов, которые должны быть включены в облако слов.
wordcloud = WordCloud(width=2200, height=2000, max_words=400,mask=mask, stopwords=STOPWORDS, background_color=”white”, random_state=42).generate(str)Первая строка кода ниже перекрашивает облако слов в цвет маски. И это дает желаемый результат.
plt.imshow(wordcloud.recolor(color_func=color),interpolation="bilinear")
plt.axis("off")
plt.show()
Если мы хотим сохранить изображение:
wordcloud.to_file("Desktop/wordcloud.png")