
Как парсить данные с KillStar с помощью Python

Table Of Content
- Основное введение, которое можно пропустить, я скопировал из моей другой статьи
- Установка расширения
- Давайте начнем!
- Убить Star Pipeline
- открыть URL в браузере
- нажать на найденный элемент
- нажать на поле ввода
- ввести содержимое в поле ввода
- нажать клавишу Enter
- Получение данных
- для извлечения текста элемента
- для извлечения ссылки элемента
- для извлечения текста элемента
- для извлечения текста элемента
- открытие URL в браузере
- нажатие на найденный элемент
- нажатие на поле ввода
- ввод содержимого в поле ввода
- нажатие клавиши Enter
- получение текста элемента
- получение ссылки элемента
- получение текста элемента
- получение текста элемента
- Запуск этой программы
Добро пожаловать снова... Еще один веб-сайт, модный бренд с элементами темноты, вкладывающий эмоциональную силу и сырую энергию в каждую нить. Мы будем использовать Python, поэтому, если у вас нет опыта работы с Python, рекомендуется освежить свои знания по этому языку.
Как всегда, перед парсингом данных с веб-сайта, нам нужно определить, какие конкретные данные мы хотим получить. После просмотра страницы я сразу увидел множество различных данных, которые мы можем получить. В этом проекте мы будем парсить название продукта, ссылку на продукт и цену.
Давайте начнем!
Основное введение, которое можно пропустить, я скопировал из моей другой статьи
Прежде всего, нам понадобится установить Python, убедитесь, что у вас установлен Python и некоторая среда разработки. Selenium Pro - это пакет для парсинга веб-страниц, который позволяет нам имитировать веб-браузер с помощью Python, возможно, лучше иметь более глубокое понимание парсинга веб-страниц. Пакет Selenium Pro - https://pypi.org/project/selenium-pro/
pip install selenium-proУстановка расширения
Загрузите Selenium Auto Code Generator из Chrome Web Store, вместо копирования и вставки xpath это инструмент поможет и упростит процесс, без необходимости копирования и вставки. Загрузить отсюда - https://chrome.google.com/webstore/detail/selenium-auto-code-genera/ocimgcpcnobcnmclomhhmjidgoiekeaf/related
Давайте начнем!
Теперь, когда мы настроили наше окружение Python, откроем пустой скрипт Python. Давайте импортируем пакет Selenium pro, который вы, надеюсь, предварительно установили в предыдущем абзаце (просто выполните pip install selenium-pro). После установки импортируйте следующие пакеты:
from selenium_pro import webdriver
import time
from selenium_pro.webdriver.common.keys import KeysМы используем браузер Google Chrome в качестве нашего графического интерфейса, но вы можете использовать другие браузеры в Selenium pro, если хотите использовать другой браузер, пожалуйста! Убедитесь, что у вас установлен конкретный браузер на вашем компьютере.
Теперь, внутри Selenium pro, нам нужно определить наш веб-браузер, давайте сделаем это с помощью следующей строки кода:
driver = webdriver.Start()Я рекомендую запустить весь ваш код до этого момента и проверить, успешно ли он выполняется, если да, то вы практически готовы продолжать!
Убить Star Pipeline
Далее следует интересная часть, нажмите на расширение DK, которое мы установили ранее, и нажмите "начать запись". Это определенно не будет сложной задачей, но к счастью у вас есть я, чтобы помочь.
Откройте веб-сайт Kiss Star и добавьте ожидание в 3 секунды для загрузки веб-сайта. Затем выполните поиск ключевого слова на веб-сайте и нажмите Enter. Чтобы добавить событие ожидания, щелкните правой кнопкой мыши на экране, затем выберите "ожидание" -> 3. Теперь, если вы нажмете на расширение, вы увидите следующий код в расширении:
# открыть URL в браузере
driver.get('[https://www.killstar.com/'](https://www.killstar.com/'))
time.sleep(2)Отлично! Этот код направит наш браузер Chrome Python на указанный выше веб-сайт, функция "time.sleep(3)" просто указывает Python подождать 3 секунды перед продолжением работы. Это необязательно, но я все равно добавил это.
После этого расширение будет искать идентификатор с помощью driver.find_element_by_pro и выполнит click(), событие click нажмет на идентификатор:
# нажать на найденный элемент
driver.find_element_by_pro(‘8hOdJ2ynXAqHDBO’).click()
time.sleep(2)
# нажать на поле ввода
driver.find_element_by_pro(‘skbNql5q1rppQft’).click()send_keys(‘black') введет ключевое слово "black", а send_keys(Keys.ENTER) нажмет Enter:
# ввести содержимое в поле ввода
driver.find_element_by_pro(‘cHffT3erKJoE7nF’).send_keys(‘black’)
# нажать клавишу Enter
driver.switch_to.active_element.send_keys(Keys.ENTER)Скопируйте код из расширения и протестируйте код до этого момента...
Получение данных
Отлично! Так что давайте продолжим запись, после ввода ключевого слова на веб-сайте Passion Planner, наведите указатель мыши на заголовок продукта, а затем щелкните правой кнопкой мыши и выберите "Извлечь текст" для получения текста продукта.
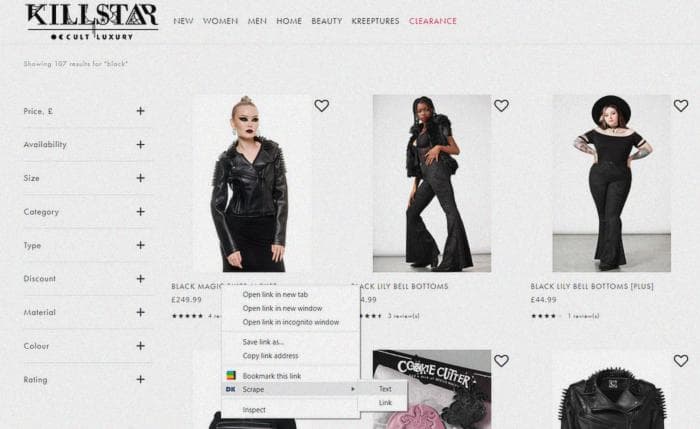
Теперь, аналогичным образом вы можете извлечь заголовок, ссылку и цену. В расширении ваше действие будет имитировано следующим образом:
# для извлечения текста элемента
product_name = list_element.find_element_by_pro('EFVHNXOc6W087AI').text
# для извлечения ссылки элемента
product_link = list_element.find_element_by_pro('rHMtu3iTZhyZwAA').get_attribute('href')
# для извлечения текста элемента
price = list_element.find_element_by_pro('jX43MMdNDT5bREb').text
# для извлечения текста элемента
reviews = list_element.find_element_by_pro('vmzW6NqMmlemyB9').textМы закончили здесь... Верьте или нет.
from selenium_pro import webdriver
import time
from selenium_pro.webdriver.common.keys import Keys
driver = webdriver.Start()
# открытие URL в браузере
driver.get('[https://www.killstar.com/'](https://www.killstar.com/'))
time.sleep(2)
# нажатие на найденный элемент
driver.find_element_by_pro('8hOdJ2ynXAqHDBO').click()
time.sleep(2)
# нажатие на поле ввода
driver.find_element_by_pro('skbNql5q1rppQft').click()
# ввод содержимого в поле ввода
driver.find_element_by_pro('cHffT3erKJoE7nF').send_keys('черный')
# нажатие клавиши Enter
driver.switch_to.active_element.send_keys(Keys.ENTER)
time.sleep(3)
# получение текста элемента
product_name=list_element.find_element_by_pro(‘EFVHNXOc6W087AI’).text
# получение ссылки элемента
product_link=list_element.find_element_by_pro(‘rHMtu3iTZhyZwAA’).get_attribute(‘href’)
# получение текста элемента
price=list_element.find_element_by_pro(‘jX43MMdNDT5bREb’).text
# получение текста элемента
reviews=list_element.find_element_by_pro(‘vmzW6NqMmlemyB9’).textЗапуск этой программы
Чтобы запустить эту программу, скопируйте код из расширения и сохраните его как файл .py > откройте терминал / командную строку и введите следующую команду:
python3 ПУТЬ/К/ВАШЕМУ/ФАЙЛУ.PYИли, если вы используете среду разработки, такую как Pycharm, просто запустите программу в ней. Когда вы запустите эту программу, вы увидите, что открывается браузер Chrome, он будет ждать несколько секунд, а затем выведет точки данных в консоль Python!
Поздравляю! Я рекомендую вам поискать способы улучшить этот проект: можете ли вы добавить интерфейс, где люди могут размещать свои ссылки? Можете ли вы добавить цикл для парсинга всех ссылок и текста со всех страниц? В противном случае, вы должны гордиться собой за то, что прошли через этот учебник!