
Как парсить данные с Rhone с помощью Python

Table Of Content
- Основное введение, которое можно пропустить, я скопировал из своей другой статьи
- Установка расширения
- Приступим!
- Rhode Pipeline
- открыть URL в браузере
- чтобы кликнуть на найденный элемент
- чтобы кликнуть на поле ввода
- чтобы ввести содержимое в поле ввода
- нажать клавишу Enter
- Получение данных
- для извлечения текста элемента
- для извлечения ссылки элемента
- для извлечения текста элемента
- открытие URL в браузере
- клик по найденному элементу
- клик по полю ввода
- ввод содержимого в поле ввода
- нажатие клавиши Enter
- получение текста элемента
- получение ссылки элемента
- получение текста элемента
- Запуск этой программы
Добро пожаловать снова... Мужская высокопроизводительная активная одежда, созданная для комфорта с технологией против запаха. Мужские футболки для тренировок и спортивные топы, созданные с учетом прочности. Мы будем использовать Python, поэтому, если у вас нет опыта работы с Python, я рекомендую освежить свои знания по этому языку.
Как всегда, перед парсингом мы должны определить, какие конкретные данные нам нужно получить. После просмотра страницы я автоматически увидел множество разных данных, которые мы можем получить. В этом проекте мы будем парсить название продукта, ссылку на продукт и цену.
Давайте начнем!
Основное введение, которое можно пропустить, я скопировал из своей другой статьи
Прежде всего, нам понадобится установить Python, убедитесь, что у вас установлен Python и какая-то среда разработки. Selenium pro - это пакет для парсинга веб-страниц, который позволяет нам имитировать веб-браузер с помощью Python, возможно, лучше иметь более глубокое понимание парсинга веб-страниц. Пакет Selenium pro - https://pypi.org/project/selenium-pro/
pip install selenium-proУстановка расширения
Скачайте Selenium Auto Code Generator из Chrome Web Store, вместо копирования и вставки xpath, этот инструмент помогает и упрощает процесс, без хлопот с копированием и вставкой. Скачать можно здесь - https://chrome.google.com/webstore/detail/selenium-auto-code-genera/ocimgcpcnobcnmclomhhmjidgoiekeaf/related
Приступим!
Теперь, когда мы настроили наше окружение Python, давайте откроем пустой скрипт Python. Давайте импортируем пакет Selenium pro, который вы, надеюсь, предварительно установили из предыдущего абзаца (просто выполните pip install selenium-pro). После установки импортируйте следующие пакеты:
from selenium_pro import webdriver
import time
from selenium_pro.webdriver.common.keys import KeysМы используем браузер Google Chrome в качестве нашего графического интерфейса, но вы можете использовать другие браузеры внутри Selenium pro, если хотите использовать другой браузер, пожалуйста, используйте его! Убедитесь, что соответствующий браузер установлен на вашем компьютере.
Теперь, внутри Selenium pro, нам нужно определить наш веб-браузер, давайте сделаем это с помощью следующей строки кода:
driver = webdriver.Start()Я рекомендую запустить весь ваш код до этого момента и проверить, успешно ли он выполняется, если да, то вы практически готовы продолжать!
Rhode Pipeline
Далее следует интересная часть, нажмите на расширение DK, которое мы установили ранее, и нажмите "начать запись". Это определенно не будет сложной задачей, но к счастью у вас есть я, чтобы помочь.

Откройте веб-сайт Rhode и добавьте ожидание в 3 секунды для загрузки веб-сайта, а затем выполните поиск ключевого слова на веб-сайте и нажмите Enter. Чтобы добавить ожидание, щелкните правой кнопкой мыши на экране, выберите "ожидание" -> 3. Теперь, если вы нажмете на расширение, вы увидите уже имеющийся код в расширении, как показано ниже.
# открыть URL в браузере
driver.get('https://www.rhone.com/')
time.sleep(3)Отлично! Это указывает нашему браузеру Chrome в Python на конкретный веб-сайт выше, функция "time.sleep(3)" просто говорит Python подождать 3 секунды перед продолжением, это необязательно, но я все равно добавил это.
После этого расширение будет искать идентификатор с помощью driver.find_element_by_pro и выполнит клик(), событие клика выполнится на идентификаторе.
# чтобы кликнуть на найденный элемент
driver.find_element_by_pro('M1iuQosdluW6LQ9').click()
time.sleep(1)
# чтобы кликнуть на поле ввода
driver.find_element_by_pro('g5YQ7XDMS93pSJa').click()и send_keys('black') введет ключевое слово "black", а send_keys(Keys.ENTER) нажмет клавишу Enter.
# чтобы ввести содержимое в поле ввода
driver.find_element_by_pro('TXXp6XcjPwWKggZ').send_keys('black')
# нажать клавишу Enter
driver.switch_to.active_element.send_keys(Keys.ENTER)
time.sleep(3)Скопируйте код из расширения и протестируйте код до этого момента...
Получение данных
Отлично! Итак, давайте продолжим запись, после ввода ключевого слова на веб-сайте Passion Planner, наведите курсор на название продукта, щелкните правой кнопкой мыши и выберите "Извлечь текст" для получения текста продукта.
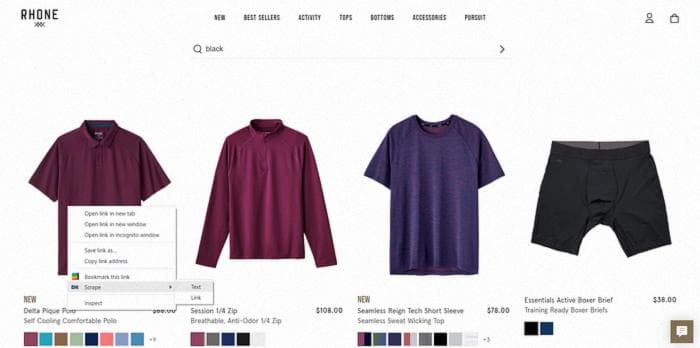
Теперь, таким же образом вы можете извлечь название, ссылку и цену. В расширении ваше действие будет имитировано следующим образом:
# для извлечения текста элемента
product_name = list_element.find_element_by_pro('dIFvOKtsT5s0VNq').text
# для извлечения ссылки элемента
product_link = list_element.find_element_by_pro('CZvpIjdnbrg5uiB').get_attribute('href')
# для извлечения текста элемента
price = list_element.find_element_by_pro('CPHhD8pxeAhUgld').textМы закончили здесь... Верите или нет.
from selenium_pro import webdriver
import time
from selenium_pro.webdriver.common.keys import Keys
driver = webdriver.Start()
# открытие URL в браузере
driver.get('[https://www.rhone.com/'](https://www.rhone.com/'))
time.sleep(2)
# клик по найденному элементу
driver.find_element_by_pro('M1iuQosdluW6LQ9').click()
time.sleep(1)
# клик по полю ввода
driver.find_element_by_pro('g5YQ7XDMS93pSJa').click()
# ввод содержимого в поле ввода
driver.find_element_by_pro('TXXp6XcjPwWKggZ').send_keys('черный')
# нажатие клавиши Enter
driver.switch_to.active_element.send_keys(Keys.ENTER)
time.sleep(3)
# получение текста элемента
product_name=list_element.find_element_by_pro(‘dIFvOKtsT5s0VNq’).text
# получение ссылки элемента
product_link=list_element.find_element_by_pro(‘CZvpIjdnbrg5uiB’).get_attribute(‘href’)
# получение текста элемента
price=list_element.find_element_by_pro(‘CPHhD8pxeAhUgld’).textЗапуск этой программы
Чтобы запустить эту программу, скопируйте код из расширения и сохраните его как файл с расширением .py. Затем откройте терминал или командную строку и введите следующую команду:
python3 ПУТЬ/К/ВАШЕМУ/ФАЙЛУ.PYИли, если вы используете среду разработки, такую как Pycharm, просто запустите программу в ней. При запуске этой программы вы увидите открытие браузера Chrome, он будет ждать несколько секунд, а затем выведет точки данных в консоль Python!
Поздравляю! Я рекомендую вам поискать способы улучшить этот проект: можете ли вы добавить интерфейс, где люди могут размещать свои ссылки? Можете ли вы добавить цикл для парсинга всех ссылок и текста со всех страниц? В противном случае, вы должны гордиться собой за то, что прошли этот учебник!