
Как парсить результаты поиска Google с помощью Node JS?
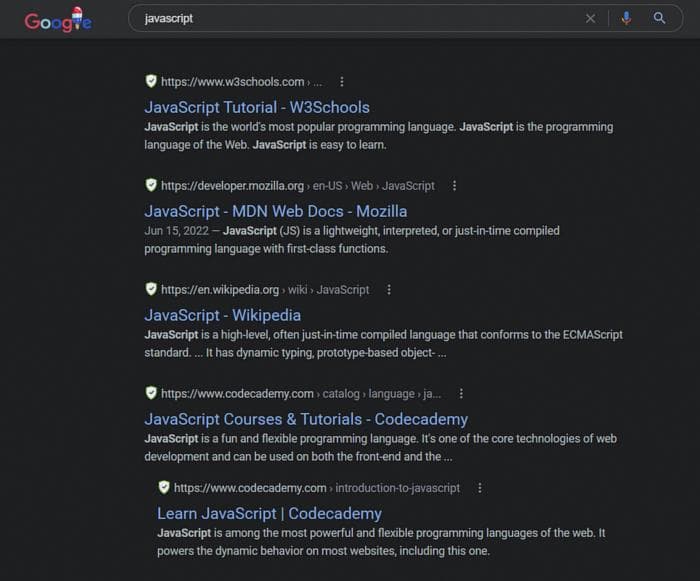
В этом посте мы научимся парсить результаты поиска Google с использованием Node JS.
Требования:
Для парсинга результатов поиска Google нам понадобится установить некоторые библиотеки:
Прежде чем начать, убедитесь, что вы настроили свой проект Node JS и установили пакеты npm - Unirest JS и Cheerio JS. Вы можете установить оба пакета по ссылке выше.
Цель:
Процесс:
Теперь у нас есть все необходимое для подготовки нашего парсера. Мы сделаем GET-запрос к нашему целевому URL, чтобы получить исходные данные HTML. Мы будем использовать библиотеку Unirest JS для получения наших HTML-данных и cheerio для парсинга извлеченных HTML-данных.
Затем мы будем искать HTML-теги для соответствующих заголовков, ссылок, отрывков и отображаемых ссылок.
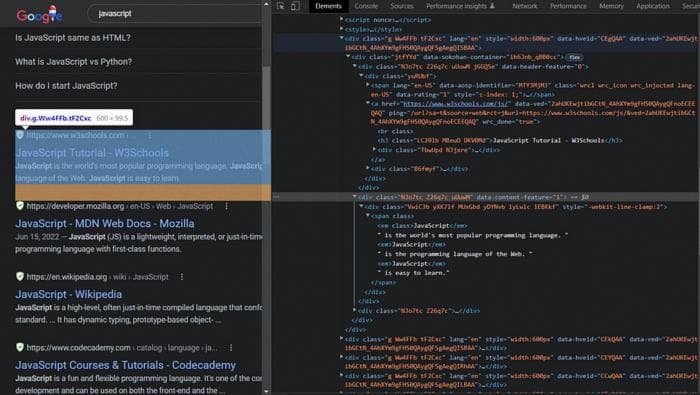
Итак, согласно этому изображению, тег для заголовка - .yuRUbf > a > h3, для ссылки - .yuRUbf > a, для отрывка - .g .VwiC3b и для отображаемой ссылки - .g .yuRUbf .NJjxre .tjvczx.
Вот наш код:
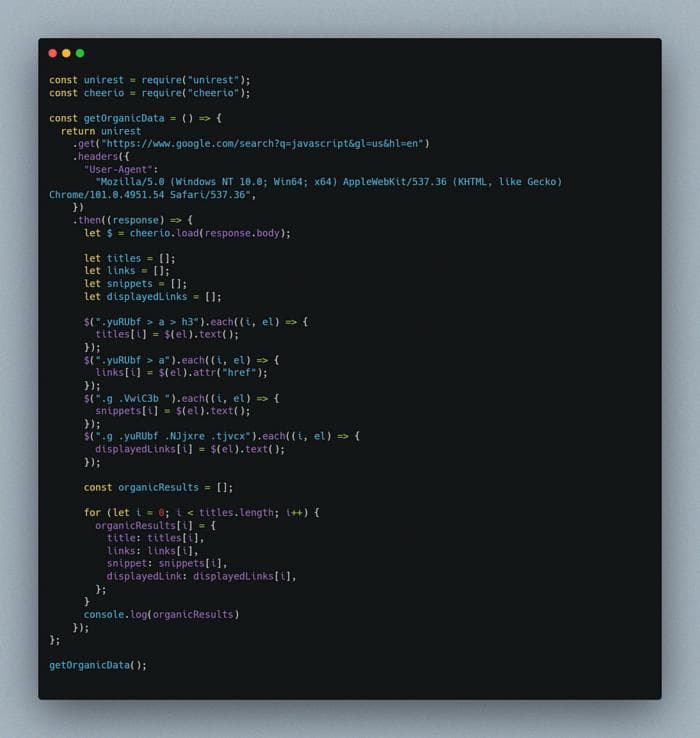
Вы можете найти код в этом репозитории GitHub.
Но одного User Agent может быть недостаточно для парсинга Google, так как он может заблокировать ваш IP-адрес для дальнейших запросов. Поэтому нам нужно больше User Agent, которые мы будем менять при каждом запросе. Вот как мы можем это сделать:
const selectRandom = () => {
const userAgents = ["Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36", "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.157 Safari/537.36", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.45 Safari/537.36", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36",
];
var randomNumber = Math.floor(Math.random() * userAgents.length); return userAgents[randomNumber];
}
let user_agent = selectRandom();
let header = {
"User-Agent": `${user_agent}`
}Передайте эту переменную header в функцию заголовка Unirest, и вы сможете менять User Agent при каждом запросе.
Примечание: Вы также можете использовать прокси-сервер при выполнении GET-запроса с помощью Unirest JS. Например:
return unirest
.get("https://www.google.com/search?q=javascript&gl=us&hl=en") .headers(header)
.proxy("your proxy");Здесь "your proxy" относится к URL прокси-сервера, который вы будете использовать для отправки запросов. Прокси-сервер скроет ваш IP-адрес, что означает, что веб-сайт не сможет идентифицировать ваш IP-адрес при выполнении запроса, что позволит сохранить ваш IP-адрес от блокировки Google.
Результаты:
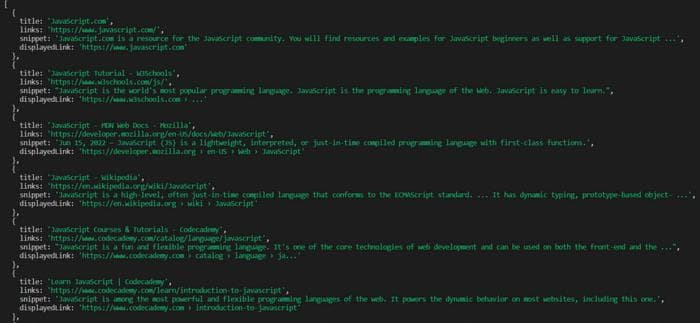
С использованием API результатов поиска Google:
Serpdog | Google Search API поддерживает все основные выделенные фрагменты, такие как графики знаний, блоки ответов, главные новости и т. д. Serpdog также предлагает 100 бесплатных запросов при первой регистрации для своих пользователей.
Парсинг иногда может занимать много времени, но заранее подготовленные структурированные данные в формате JSON могут сэкономить вам время.
const axios = require('axios');axios.get('[https://api.serpdog.io/search?api_key=APIKEY&q=javascript&gl=us'](https://api.serpdog.io/search?api_key=APIKEY&q=coffee&gl=us%27))
.then(response => {
console.log(response.data);
})
.catch(error => {
console.log(error);
});Результаты:

Дополнительные ресурсы:
Заключение:
В этом руководстве мы научились парсить результаты поиска Google. Не стесняйтесь задавать мне вопросы в комментариях👇🏻. Спасибо за чтение!