
Как собрать данные и создать отчет в Excel

Руководство на Python о том, как собрать данные с веб-сайта и создать отчет в Excel для дальнейшего анализа.
Вы когда-нибудь задумывались о анализе определенного веб-сайта? Например, анализ популярных ключевых слов или услуг. И какой лучший инструмент для анализа, чем Excel? В этой статье я покажу вам, что достичь этого может быть проще, чем вы думаете.
Чтобы запустить пример, загрузите этот Jupyter notebook.
Вот несколько ссылок, которые могут вас заинтересовать:
- [Маркировка и инжиниринг данных для разговорного ИИ и аналитики](https://www.humanfirst.ai/)- [Data Science для бизнес-лидеров](https://imp.i115008.net/c/2402645/880006/11298) [Курс]- [Введение в машинное обучение с использованием PyTorch](https://imp.i115008.net/c/2402645/788201/11298) [Курс]- [Станьте менеджером по продукту роста](https://imp.i115008.net/c/2402645/803127/11298) [Курс]- [Глубокое обучение (серия Adaptive Computation and ML)](https://amzn.to/3ncTG7D) [Электронная книга]- [Бесплатные тесты навыков для Data Scientists и Machine Learning Engineers](https://aigents.co/skills)Некоторые из приведенных выше ссылок являются партнерскими ссылками, и если вы перейдете по ним и совершите покупку, я получу комиссию. Имейте в виду, что я размещаю ссылки на курсы из-за их качества, а не из-за получения комиссии от ваших покупок.
1. Определение того, что нужно спарсить
В первую очередь, вам нужно определить, что именно вы хотите спарсить. В моем примере это последние статьи с TechCrunch (отмечены красным квадратом на изображении ниже). Для каждой статьи я хочу спарсить заголовок, краткое содержание и URL.
Давайте проанализируем HTML в веб-браузере (щелкните правой кнопкой мыши на веб-странице -> "Исследовать элемент") и найдем шаблон в HTML-элементах, которые форматируют последние статьи (отмечены синим квадратом на изображении ниже).
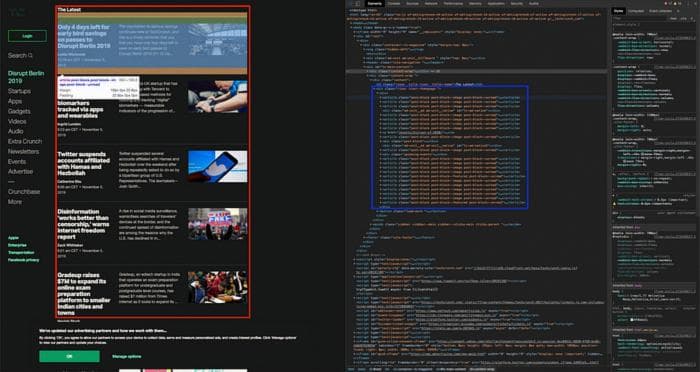
Статьи отмечены элементами: <article class="post-block post-block--image post-block--unread">. При более детальном рассмотрении мы получаем элементы с заголовком, содержанием и атрибутом с URL статьи.
2. Парсинг
Теперь, когда я определил элементы, мне нужно их распарсить. Давайте получим веб-страницу TechCrunch и распарсим ее с помощью HTML-парсера BeautifulSoup.
url = "https://techcrunch.com/"
response = requests.get(url)
soup = bs4.BeautifulSoup(response.text, "html.parser")
В распарсенном выводе выше есть элементы <div>, а не <article> - вы можете прочитать больше о том, почему это происходит в ответе на StackOverflow.
Чтобы распарсить статьи из распарсенного HTML, мне нужно определить HTML-элементы:
- родительский элемент статьи помечен тегом
divс атрибутамиclass="post-block post-block--image post-block--unread" - заголовок и URL находятся в отдельном блоке:
class="post-block__title__link",class="post-block__content"соответственно.
Ниже приведен код, который распарсивает заголовок статьи, краткое содержание и URL, и добавляет их в списки.
article_titles, article_contents, article_hrefs = [], [], []
for tag in soup.findAll("div", {"class": "post-block post-block--image post-block--unread"}):
tag_header = tag.find("a", {"class": "post-block__title__link"})
tag_content = tag.find("div", {"class": "post-block__content"})
article_title = tag_header.get_text().strip()
article_href = tag_header["href"]
article_content = tag_content.get_text().strip()
article_titles.append(article_title)
article_contents.append(article_content)
article_hrefs.append(article_href)3. Создание отчета в Excel
Я разобрал содержимое веб-страницы, теперь мне нужно сохранить его в файл Excel. С помощью DataFrame из библиотеки pandas мы можем создать отчет в Excel с помощью нескольких команд. Давайте создадим DataFrame из списков.
df = pd.DataFrame({"Заголовок": article_titles, "Содержание": article_contents, "Ссылка": article_hrefs})
def auto_adjust_excel_columns(worksheet, df):
for idx, col in enumerate(df): _# перебираем все столбцы_
series = df[col]
max_len = (
max((
series.astype(str).map(len).max(), _# длина самого большого элемента
len(str(series.name)), _# длина названия столбца/заголовка
))
+ 1
) _# добавляем немного дополнительного пространства
worksheet.set_column(idx, idx, max_len) _# устанавливаем ширину столбца_По умолчанию столбцы в Excel не автоматически подстраиваются под содержимое, поэтому нам нужно установить ширину столбцов (максимальное значение между заголовком столбца и самым большим элементом в столбце). Ниже приведен код, который автоматически подстраивает столбцы и создает файл Excel из DataFrame.
writer = pd.ExcelWriter('TechCrunch_latest_news.xlsx', engine='xlsxwriter')
df.to_excel(writer, sheet_name='Лист1', index=False)
auto_adjust_excel_columns(writer.sheets['Лист1'], df)
writer.save()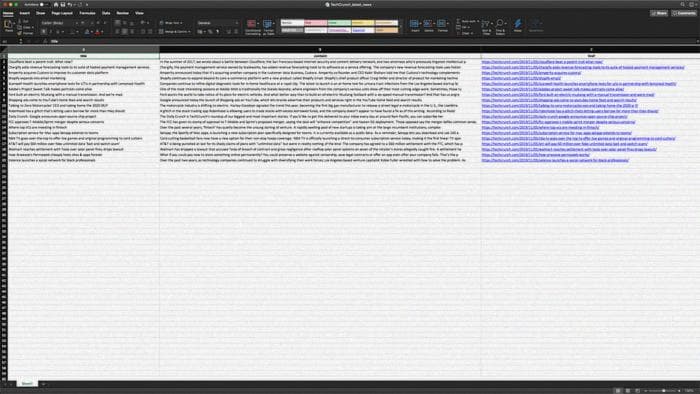
Заключение
В этой статье я показал, как парсить последние статьи с TechCrunch и сохранять их в отчете Excel, который может быть использован не программистами. Python и его библиотеки позволяют нам достичь этого с помощью нескольких команд.
Каждый веб-сайт отличается и требует некоторого ручного поиска правильных элементов для парсинга. Дайте мне знать, если вам нужна помощь с парсингом.
Прежде чем вы уйдете
Подпишитесь на меня в Twitter, где я регулярно твиттерю о Data Science и Machine Learning.
