
Парсинг данных с Google и визуализация с помощью облака слов
Вы пробовали искать свое имя в Google? Или имя кого-то другого? Какое самое частое слово ассоциируется с вашим именем? В этом руководстве мы это выясним :)
Требования:
- Python
- Интернет-соединение :)
В этом руководстве есть 2 раздела: "Парсинг" и "Визуализация".
Парсинг
Установка Scrapy:
pip install scrapyПервая попытка
Создадим наш проект.
scrapy startproject google
cd googleПопробуем найти ваше имя в Google. Я предполагаю, что ваше имя - "Сукиян".
Получение всего текста
Давайте попробуем получить весь текст с веб-страницы. Я попробую с этим URL-адресом
[https://www.aljazeera.com/news/2019/06/israeli-forces-settlers-enter-al-aqsa-mosque-compound-190602065712978.html](https://www.aljazeera.com/news/2019/06/israeli-forces-settlers-enter-al-aqsa-mosque-compound-190602065712978.html`)(Одна из первых новостей, которую я получил сегодня утром)
Создайте файл
google/google/spiders/test.pyИ напишите
import scrapyclass TestSpider(scrapy.Spider):
name = 'test'# Сообщите Scrapy, что мы хотим начать парсинг с этих страниц
start_urls = [
'[https://www.aljazeera.com/news/2019/06/israeli-forces-settlers-enter-al-aqsa-mosque-compound-190602065712978.html'](https://www.aljazeera.com/news/2019/06/israeli-forces-settlers-enter-al-aqsa-mosque-compound-190602065712978.html')]# Что мы собираемся делать после разрешения страницы
def parse(self, response):
# Мы возвращаем словарь с этими данными
yield {
# response.css - это селектор в стиле CSS.
# ::text означает, что мы хотим получить только текст. Если мы не добавим ::text
# Мы получим <title>Israeli forces and settlers ...</title>
# Когда мы добавляем text, мы получаем 'Israeli forces and settlers ...'
'title': response.css('title::text').get(),
# То же самое с `p`, мы выбираем текст элемента p
# Но обратите внимание, что мы используем `getall` вместо `get`
# `get` выберет только один элемент.
# В то время как `getall` выберет все элементы и вернет список
'text': response.css('p::text').getall()
}Теперь попробуйте запустить
scrapy crawl testВы увидите результат в командной строке.
Давайте попробуем записать результат в файл с помощью
scrapy crawl test -o result.jsonТеперь вы можете увидеть результат в формате JSON в файле result.json
Получение ссылок с Google
Давайте попробуем собрать много URL-адресов с Google.
Прежде всего, перейдите в settings.py и убедитесь, что
…
ROBOTSTXT_OBEY = False
…
import scrapy
import re
def is_google(a):
url = a.attrib['href']
return bool(re.search("/search", url))
class TestSpider(scrapy.Spider):
name = "test"
# Как получить начальный URL
# Ищите `sukijan` в Google. Затем перейдите на вторую страницу и нажмите на результат первой страницы. Вы увидите, что теперь URL включает параметр `start`. Мы будем использовать его для пагинации.
# Также обратите внимание на параметр `q=sukijan`. Это наше ключевое слово.
# Мы используем `% start for start in range(0, 100, 10)`, чтобы сгенерировать URL-адреса, которые мы хотим собрать.
# Таким образом, будет сгенерирован список URL-адресов, например:
# [q=sukijan start=0, q=sukijan start=10, q=sukijan start=20, q=sukijan start=30... до 100]
start_urls = [
'https://www.google.com/search?q=sukijan&safe=strict&ei=sLTvXL_KH4zfz7sPpZOBuA4&start=%s&sa=N&ved=0ahUKEwi_4un2icPiAhWM73MBHaVJAOc4ChDx0wMIjQE&cshid=1559213273144254&biw=1680&bih=916' % start for start in range(0, 100, 10)
]
def parse(self, response):
# Что такое `jfp3ef a`?
# Если вы выполните `scrapy shell https://www.google.com/search?q=Sukijan&oq=sukijan&aqs=chrome.0.69i59j0l5.1739j0j7&sourceid=chrome&ie=UTF-8#ip=1`
# И затем выполните `view(response)`, откроется браузер
# Затем выполните инспектирование элемента, найдите ссылку и вы увидите, что большинство ссылок попадают под класс `.jfp3ef`
for href in response.css('.jfp3ef a'):
# Мы хотим открыть эти ссылки, но не хотим открывать URL-адреса Google
# Например, URL-адрес `More images for Sukijan` и т.д.
if not is_google(href):
# Это означает 'Привет scrapy, перейди по этому URL-адресу.
# Когда ты его найдешь, запусти функцию parse_text на нем.
yield response.follow(href, self.parse_text)
def parse_text(self, response):
# Функция get_text принимает ответ
# Затем она берет весь текст, независимо от того, находится ли он в теге <p>, <h1>, <h2> и т.д.
# Но она оставляет все внутри тегов <script> и <style>
# Она также удаляет `\r`, `\n`, `\t`
# Кроме того, она объединяет весь текст в строку, а не в список
def get_text(response):
with_duplicated_space = ' '.join(response.xpath(
'.//text()[not(ancestor::script|ancestor::style|ancestor::noscript)]').extract()).strip().replace("\r", "").replace("\n", "").replace("\t", "")
without_duplicated_space = re.sub(
' +', ' ', with_duplicated_space).strip()
return without_duplicated_space
yield {
'title': response.css('title::text').get(),
'text': get_text(response)
}Хорошо, хорошо, здесь много всего происходит. Пожалуйста, дайте мне знать, если мои объяснения вызывают путаницу. Я всегда открыт для обратной связи. Напишите мне в твиттере @muhajirdev.
Шагните вперед, удалите result.json и снова запустите scrapy crawl test -o result.json. Подождите, пока процесс сбора данных не завершится.
Визуализация с помощью Wordcloud
Хорошо, теперь откройте jupyter notebook. Вы можете установить его с помощью следующих команд:
Python 3:
python3 -m pip install --upgrade pip
python3 -m pip install jupyterPython 2:
python -m pip install --upgrade pip
python -m pip install jupyterВ зависимости от вашей версии Python.
Вы можете прочитать более подробные инструкции по установке здесь https://jupyter.org/install.html.
Запустите следующую команду в командной строке:
jupyter notebookОткроется браузер. Создайте новый файл:
File > New Notebook > Python 3import jsontext = ''
with open("result.json", "r") as read_file:
data = json.load(read_file)
for i in data:
text = text + i['text']from wordcloud import WordCloud, STOPWORDS, ImageColorGenerator
import matplotlib.pyplot as pltwordcloud = WordCloud(background_color="white").generate(text)stopwords = set(STOPWORDS)
# Большая часть моего контента находится на бахаса Индонезия. Поэтому я добавляю больше стоп-слов на бахаса Индонезия
stopwords.update(
[
"di", "yang", "dengan", "dan", "pada", "juga",
"itu", "dalam", "kepada" "untuk", "tersebut", "tidak", "ini",
"dari", "sebagai", "ada", "ke", "adalah", "akan", "saat", "kembali"
"oleh", "karena", "tak", "ia", "setelah", "sudah", "atau", "untuk", "bahwa",
"saya", "next", "play", "menjadi", "dia", "telah", "seperti", "oleh",
"duration", "minutes", "kami", "kita", "WIB", "ago", "now", "orang",
"mereka", "Namun", "Video", "seconds", "views",
]
)wordcloud = WordCloud(background_color="white", stopwords=stopwords, scale=2).generate(text)Хорошо, теперь давайте попробуем визуализировать его:
plt.figure()
plt.imshow(wordcloud, interpolation="bilinear")
plt.axis("off")
plt.show()
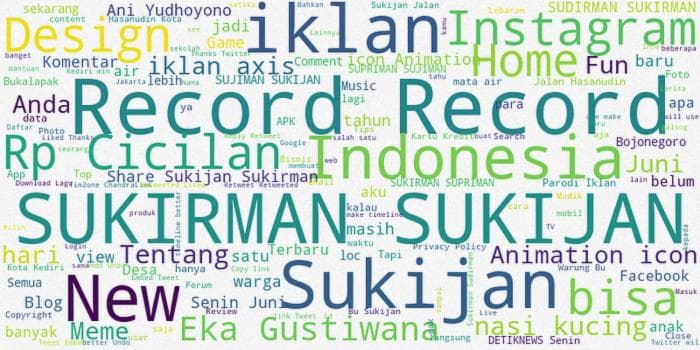
Вы можете видеть, что Sukijan тесно связан с Индонезией, Sukirman, также есть Eka Gustiwana.
Но как сохранить это в файл? Просто выполните следующую команду:
wordcloud.to_file("sukijan.png")Теперь должен быть файл с названием sukijan.png, содержащий облако слов.
Буду рад услышать от вас отзывы :). Напишите мне в твиттере @muhajirdev
_Этот пост был изначально написан на _https://muhajir.dev/writing/scraping-and-visualizing-wordcloud/
Чтение будет проще на https://dev.to/muhajirdev/scraping-from-google-visualizing-most-common-word-with-wordcloud-4mko так как там много кода :)