
Парсинг JSON API в Google DataStudio
3 шага для интеграции внешних данных в рабочий процесс вашей компании

Недавно я много работал над сбором знаний из Интернета и их доступностью для анализа мной и другими. В частности, я изучал API лучших веб-сайтов и настраивал процессы для получения информации с конечной точки и ее хранения в хранилище данных, к которому можно обращаться по требованию.
Использование JSON API вместо традиционного подхода к доступу к веб-странице и извлечению информации из HTML/CSS имеет множество преимуществ. В частности, данные находятся в аккуратном, структурированном формате, что облегчает работу с ними и исследование, а также делает их менее подверженными изменениям на веб-сайте. Кроме того, в JSON API часто доступно гораздо больше данных, чем отображается на странице, что позволяет получить доступ к "секретной" информации.
В этой статье я хотел бы описать подход, который я использовал, чтобы показать вам, насколько это может быть просто. В качестве краткого обзора, мы:
- начнем с конечной точки API
- используем Scrapy и Scraping Hub для планирования задач парсинга с помощью Python
- извлечем и обработаем данные с помощью Google Scripts
- передадим данные в Google BigQuery, где они будут храниться
- создадим быстрый и простой инструментарий с помощью Google DataStudio
Лучшая часть: все это бесплатно (с использованием 12-месячной пробной версии Google)!
Для успешной реализации подобного проекта требуется знание API, Python, Google Scripting и создание инструментов для анализа данных. Это отражает множественные уровни знаний, которыми должен обладать хороший аналитик данных, работающий для онлайн-компании. Если у вас нет всех необходимых навыков, не беспокойтесь, читайте дальше! Если вы запутаетесь, остановитесь и прочитайте немного больше информации об этой области перед продолжением.
Конечная точка API
API Endpoint, с которым мы будем экспериментировать, - это Instagram, поскольку он широко используется и применим во многих отраслях. Мы будем стремиться отслеживать публикации наших основных конкурентов и определить, какие из них привлекают больше подписчиков.
Конечная точка выглядит примерно так:
https://www.instagram.com/yourHandle/?__a=1которая, в случае учетной записи "instagram", вернет данные JSON, выглядящие так:
{
**"logging_page_id"**:"profilePage_25025320",
**"show_suggested_profiles"**:true,
**"graphql"**:{
**"user"**:{
**"biography"**:"Discovering and telling stories from around the world. Founded in 2010 by @kevin and @mikeyk.",
**"blocked_by_viewer"**:false,
**"country_block"**:false,
**"external_url"**:null,
**"external_url_linkshimmed"**:null,
**"edge_followed_by"**:{
**"count"**:244279586
},
...Вау, это много подписчиков.
Если вы хотите следовать за мной, вы можете получить JSON, просто вставив URL в адресную строку, а затем использовать инструмент, такой как jsonformatter.curiousconcept.com, чтобы разобрать JSON в более читаемый формат.
Изучая JSON, мы видим, что конкретная информация, которая нас интересует, публикации, находится под:
response['graphql']['user']['edge_felix_combined_post_uploads']['edges']И данные (показывающие только те, которые являются актуальными) для одной из этих публикаций выглядят так:
**"node"**:{
**"__typename"**:"GraphVideo",
**"id"**:"1827796522823934046",
**"edge_media_to_caption"**:{
**"edges"**:[
{
**"node"**:{
**"text"**:"Hello, world! Meet four love-struck Pacific parrotlets named Winter, Sprig, River and Willow ([@freyaeverafter_](http://twitter.com/freyaeverafter_))."
}
}
]
},
**"shortcode"**:"Bldo0DgnWBe",
**"edge_media_to_comment"**:{
"count":526
},
**"taken_at_timestamp"**:1532110486,
**"dimensions"**:{
**"height"**:1340,
**"width"**:750
},
**"display_url"**:"[https://instagram.fsin2-1.fna.fbcdn.net/vp/f9785a26d7120833ba3b99ec3e5eb13a/5B5EB778/t51.2885-15/e15/37119199_422055764959713_4492943422667096064_n.jpg](https://instagram.fsin2-1.fna.fbcdn.net/vp/f9785a26d7120833ba3b99ec3e5eb13a/5B5EB778/t51.2885-15/e15/37119199_422055764959713_4492943422667096064_n.jpg)",
**"edge_liked_by"**:{
**"count"**:13720
},
**"edge_media_preview_like"**:{
**"count"**:13720
},
**"owner"**:{
**"id"**:"25025320"
},
**"is_video"**:true,
**"is_published"**:true,
**"product_type"**:"igtv",
**"title"**:"Birds of a Feather with [@freyaeverafter_](http://twitter.com/freyaeverafter_)",
**"video_duration"**:91.891
}Хорошо, у нас есть отправная точка. В вашем случае у вас может быть API конкурента или любое другое количество вещей, но структура будет такой же. Вам следует определить, как информация возвращается и какую именно информацию вы хотите извлечь. Затем последующие процессы будут аналогичными.
Парсинг с помощью Scrapy
Теперь, когда мы знаем, какие данные нам нужны, изучив JSON, нам нужно настроить процедуру, которая будет общаться с конечной точкой и получать необходимую информацию в соответствии с заданным расписанием.
Инструмент, который мы будем использовать для этого, - www.scrapinghub.com, который создан с использованием очень популярной библиотеки Python для парсинга веб-страниц - Scrapy. У Scrapy и Scraping Hub есть много хороших учебных пособий по основам настройки, которые я оставлю вам для прочтения.
Одно замечание, которое я хочу сделать здесь, заключается в том, что большая часть документации по Scrapy говорит о парсинге традиционного HTML/CSS документа с использованием CSS Selectors или XPath для получения нужной информации, но ни один из них не применим здесь, потому что мы имеем дело непосредственно с JSON-ответом. Вместо этого для парсинга содержимого вы должны использовать что-то вроде:
**import** jsondata = json.loads(response.css('::text').extract_first())Здесь мы считываем JSON-ответ из нашей конечной точки API в виде текста (и извлекаем первый и единственный результат), а затем, используя библиотеку json в Python, разбираем текст в словарь Python.
Данные, которые мы хотим, затем могут быть получены, как ранее описано выше
posts = data['graphql']['user']['edge_felix_combined_post_uploads']['edges']что даст группу (список Python) постов. Эти списки могут быть перебраны для создания элемента, который будет возвращен в Scrapy, как в случае с традиционным парсером HTML/CSS.
**for** post **in** posts:
**yield** postВо многих случаях вам не нужно или не хотите хранить все данные, возвращаемые в JSON-объекте, поэтому на этом этапе вы должны выбрать поля, которые вам интересны. В случае с Instagram API, о котором мы упоминали выше, мы хотели бы сохранить следующие данные:
keep_fields = ["__typename", "id", "edge_media_to_caption", "shortcode", "edge_media_to_comment", "taken_at_timestamp", "display_url", "edge_liked_by", "edge_media_preview_like", "owner", "is_video", "is_published", "product_type", "title", "video_duration"]
**for** post **in** posts:
**yield** { k: post[k] for k in keep_fields }После того, как наша задача работает на Scraping Hub и возвращает результаты, пришло время настроить планирование для этой задачи и переместить ее в место, где мы сможем использовать полученные данные!
Обратите внимание, что возможно планировать задачи в Scraping Hub, если вы заплатите ежемесячную плату в размере $9, но мы будем использовать Google Scripts, чтобы избежать этой платы и продолжить использовать бесплатную учетную запись на данный момент.
Обработка с помощью Google Scripts
Прежде чем мы продолжим и обработаем данные с помощью Google Scripts, давайте настроим планирование с помощью Google Scripts. Это возможно с использованием Scrapy API /run, простой пример того, как мы могли бы сделать это с помощью Google Scripts, приведен ниже. Эта задача должна быть запланирована для запуска с использованием системы триггеров Google в регулярных интервалах, которые вы хотите просканировать, например, один раз в день, один раз в час.
/**
* [@summary](http://twitter.com/summary) Запуск задания Scrapy.
*
* Эквивалентный curl-запрос:
* curl -u APIKEY: [https://app.scrapinghub.com/api/run.json](https://app.scrapinghub.com/api/run.json) -d project=PROJECT -d spider=SPIDER
*
* [@params](http://twitter.com/params) {String} projectId
* [@params](http://twitter.com/params) {String} spiderName
*
* [@returns](http://twitter.com/returns) {Object}
*/
**function** runJob(projectId, spiderName) {
var url = '[https://app.scrapinghub.com/api/run.json'](https://app.scrapinghub.com/api/run.json') +
'?apikey=' + globVar('apiKey');
var options = {
'method' : 'post',
'payload' : {
'project': projectId,
'spider' : spiderName,
};
};
**return** UrlFetchApp.fetch(url , options);
}Пройдя этот путь, мы можем захотеть обработать данные, чтобы изменить некоторые из записей в соответствии с нашими требованиями. Например, в вышеприведенном случае результат, возвращаемый для edge_media_to_caption, является многоуровневым словарем, поэтому мы можем обработать его, чтобы вернуть только текст подписи. В других случаях мы можем захотеть сопоставить соглашения об именовании на веб-сайтах наших конкурентов с теми, которые мы используем на нашем собственном веб-сайте.
Обратите внимание, что это также можно сделать непосредственно в Scrapy до того, как мы вернем элемент, или в качестве промежуточного программного обеспечения, это обычно лучшая идея, но иногда обработка в Google Scripts после извлечения из Scrapy может быть проще.
Сохранение в Google BigQuery
Для сохранения всех данных, которые мы парсим, мы будем использовать Google BigQuery. Процесс настройки здесь довольно простой. Предполагая, что у нас уже есть учетная запись, мы можем создать новый набор данных и таблицу с выбранными нами полями и типами данных. После этого мы записываем соответствующие идентификаторы и имена и возвращаемся в Google Scripts.
Чтобы отправить данные в Google BigQuery, сначала мы должны отформатировать их в формат CSV. Это может быть немного сложно, особенно когда вы имеете дело с контентом, созданным пользователями, который имеет неожиданные длины, форматы и символы, но следующий код выполняет задачу.
/**
* Преобразует массив в файл CSV.
*
* @param {Array} data Данные, которые нужно преобразовать в CSV.
*
* @returns Сгенерированный из массива файл CSV.
*/
function convertArrayToCsvFile(data) {
var csvFile = undefined;
// Проход по данным в диапазоне и создание строки с данными CSV.
if (data.length > 1) {
var csv = "";
for (var row = 0; row < data.length; row++) {
// В каждом столбце проверяем, есть ли запятая, и затем добавляем ее.
for (var col = 0; col < data[row].length; col++) {
if (data[row][col] != undefined) {
if (data[row][col].toString().indexOf(",") != -1) {
data[row][col] = "\"" + data[row][col] + "\"";
};
};
};
// Объединяем столбцы каждой строки.
// Добавляем символ возврата каретки в конец каждой строки, кроме последней.
if (row < data.length-1) {
csv += data[row].join(",").replace(/\r/g, '').replace(/\n/g, '') + "\r\n";
}
else {
csv += data[row];
}
}
csvFile = csv;
}
return csvFile;
}Полученный CSV-файл затем может быть сохранен в Google Drive. После сохранения данных в правильном формате их можно отправить в BigQuery с помощью следующего скрипта:
/**
* Вставляет данные в таблицу BigQuery из файла CSV.
*
* @param {Object} data Файл CSV для загрузки в BigQuery.
* @param {String} projectId Проект BigQuery для вставки.
* @param {String} datasetId Набор данных BigQuery для вставки.
* @param {String} tableId Таблица BigQuery для вставки.
*/
function sendToBigQuery(data, projectId, datasetId, tableId){
// Запустите этот код, чтобы получить правильные разрешения для BQ.
DriveApp.getRootFolder();
// Определите задание вставки.
var insertJob = {
configuration:{
load:{
destinationTable:{
projectId: projectId,
datasetId: datasetId,
tableId: tableId
}
},
}
};
// Отправляем задание в BigQuery.
var job = BigQuery.Jobs.insert(insertJob, projectId,
data.getBlob().setContentType('application/octet-stream'));
Logger.log(job.status.state);
var jobId = job.jobReference.jobId;
// Ждем ответа о задании.
var sleepTimeMs = 500;
while (job.status.state !== 'DONE'){
Utilities.sleep(sleepTimeMs);
job = BigQuery.Jobs.get(projectId, jobId);
Logger.log(job.status.state);
}
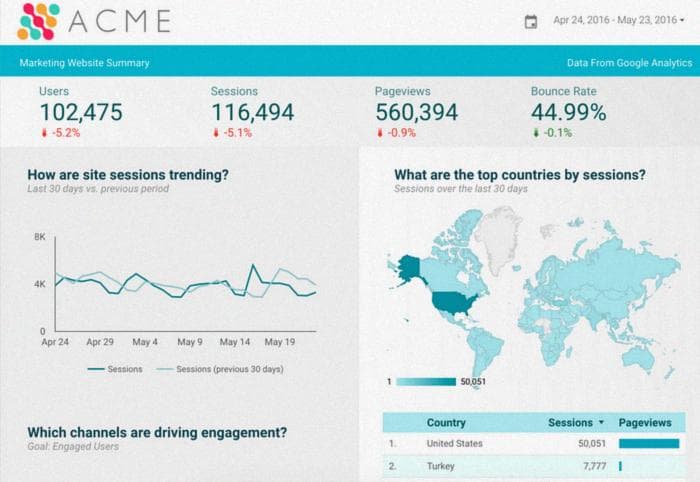
}Создание красивых панелей инструментов с помощью Google DataStudio
Я являюсь большим поклонником Google DataStudio, он отлично сочетается с BigQuery и позволяет быстро создавать красивые и долгоиграющие отчеты на основе ваших данных.
В данном случае мы создадим новый отчет в Google DataStudio и создадим источник данных с помощью подключения BigQuery. Поскольку все это Google, намного меньше нужно делать для типизации или форматирования данных, так как все это должно быть автоматически решено.
Заключение
Хотя это всего лишь обзор и не содержит кода или инструкций для всего процесса, я надеюсь, что это дает вам представление о том, что возможно. В заключение, мы:
- определили данные на конечной точке API
- использовали Scrapy и Scraping Hub для обхода данных с регулярными интервалами
- запланировали обходы и обработали данные с помощью Google Scripts
- переслали данные в Google BigQuery, где они хранятся
- создали быстрый и простой инструментарий с помощью Google DataStudio
Любите парсить данные? Ознакомьтесь с этой статьей о парсинге Memrise для изучения поведения пользователей: Memrise Data Scrape & Analysis.
_Если вам понравилось прочитать это, пожалуйста, не забудьте поставить пару или две, или три аплодисментов_👏👏👏🔄
Если у вас есть вопросы о настройке чего-то подобного, не стесняйтесь обращаться.