
Парсинг результатов поиска Google с использованием BeautifulSoup

Table Of Content
- Парсинг может облегчить вашу жизнь в работе.
- Документация Beautiful Soup - документация Beautiful Soup 4.9.0
- Beautiful Soup - это библиотека Python для извлечения данных из HTML и XML файлов. Она работает с вашим парсером для...
- Парсинг веб-страниц
- Установка
- Установка библиотек
- Код
- Первая страница
- Вторая страница
- Заключение
- dataScienceLab/googleScraping.ipynb в ветке main · naenumtou/dataScienceLab
- Все статистические модели / машинное обучение / компьютерное зрение / финансовые модели / NLP / техники Python / библиотеки...
Парсинг может облегчить вашу жизнь в работе.
Сегодня мы попробуем сделать простой веб-парсинг с вымышленной ситуацией, в которой мы хотим получить данные из Google с помощью набора ключевых слов (которых может быть больше, чем одно) и хотим просмотреть краткое содержание результатов, отображаемых на странице поисковой выдачи. Мы можем захотеть просмотреть результаты более чем на одной странице, может быть 5 или 10 страниц.
Если мы должны искать по одному слову, читать результаты по одной странице, это займет слишком много времени для результатов по одному слову или одной странице. Поэтому реализация с использованием BeautifulSoup, который является библиотекой для работы с парсингом веб-страниц на Python, может быть более интересным решением.
Документация Beautiful Soup - документация Beautiful Soup 4.9.0
Beautiful Soup - это библиотека Python для извлечения данных из HTML и XML файлов. Она работает с вашим парсером для...
Парсинг веб-страниц
Представленный выше сценарий не является ничем новым, поскольку в наши дни сбор данных с Интернета является распространенной и обычной практикой во многих организациях. Существует множество способов сбора данных, включая использование API, что имеет свои преимущества, такие как ясный формат и более быстрая передача данных, и более простая реализация.
Однако, в данной статье мы рассмотрим другой популярный способ, известный как "парсинг веб-страниц".
В данном случае мы хотим выполнить парсинг веб-страницы Google, поэтому весь представленный код зависит от структуры страницы Google. При использовании этого кода на других веб-страницах потребуется некоторая модификация, хотя, в целом, понимание работы парсинга веб-страницы полезно даже для стандартных страниц Google. Тем не менее, код должен быть обновлен со временем, так как исходный код Google может измениться в любой момент.
Установка
Поскольку использование библиотеки requests в Python может столкнуться с проблемой проверки User-agent, которая проверяет, является ли входящий запрос человекочитаемым или является ли он командой, отправленной из скрипта, а также наличие JavaScript на странице Google, что создает проблемы при парсинге, мы решили использовать WebDriver для загрузки исходного кода в формате lxml.
Однако, поскольку весь код выполняется в Google Colab, необходимо настроить WebDriver в Colab. Для этого сначала установим необходимые библиотеки: Selenium и Chromium в качестве веб-браузера.
Введите следующие команды в Google Colab:
# Установка библиотек
!pip install selenium
!apt-get update # Обновление Ubuntu для правильной установки apt
!apt install chromium-chromedriver
!cp /usr/lib/chromium-browser/chromedriver /usr/binКод
Начнем с импорта всех необходимых библиотек. Разделим код на две части: первая часть будет отвечать за управление WebDriver для поиска, а вторая часть - за парсинг данных. Давайте сначала рассмотрим первую часть.
Установим Chrome в качестве веб-браузера, используя Selenium в качестве WebDriver. Здесь можно добавить дополнительные параметры для Chrome, такие как ‘--headless’, чтобы не отображать окно программы.
Если вы выполняете код локально, возможно, потребуется другая настройка.
Далее идет код, отвечающий за поиск. Здесь мы определяем слова для поиска и количество страниц, которые нужно просканировать. В данном примере мы используем слова "матум" и "коронавирус" и сохраняем их в переменной searchWords в виде строки.
После определения слов для поиска мы заменяем пробелы на знак "+" с помощью .replace(), так как при поиске с помощью URL Google использует знак "+" для объединения нескольких слов. Таким образом, URL для поиска двух слов будет выглядеть следующим образом:
https://google.com/search?q=матум+коронавирусОбычно Google отображает 10 результатов поиска на одной странице. Однако это может варьироваться в зависимости от рекламы, которая отображается каждым интернет-провайдером. По умолчанию количество результатов на странице равно 10. Чтобы указать номер страницы в URL, используется &start=, где первая страница имеет значение 0. Таким образом, для получения результатов со второй страницы URL будет выглядеть следующим образом:
# Первая страница
https://google.com/search?q=матум+коронавирус&start=0
# Вторая страница
https://google.com/search?q=матум+коронавирус&start=10Чтобы решить эти проблемы, можно использовать while loop. Здесь мы устанавливаем начальное значение searchPages = 0 и в цикле while statement увеличиваем его на 10. Таким образом, URL будет обновляться с каждой итерацией цикла.
После определения всех параметров можно начать процесс парсинга. Здесь мы определяем URL в переменной searchURL внутри цикла while statement, так как searchPages должен увеличиваться на 10 с каждой итерацией. Затем мы используем заранее определенный driver для выполнения команды .get(searchURL). Можно добавить time.sleep(3), чтобы не вызывать слишком частые запросы и избежать сбоев в программе.
Затем мы определяем переменную soup, которая будет содержать результаты парсинга HTML с помощью BeautifulSoup(driver.page_source, ‘lxml’). Здесь мы получаем все необходимые данные, но нам нужно извлечь только нужную информацию для удобного чтения.
Чтобы извлечь только интересующую нас информацию, мы используем цикл for loop. Например, если мы хотим получить заголовок веб-страницы, мы используем .find_all(‘h3’) для элемента h3. Если мы хотим получить содержимое страницы результатов, мы используем .find_all(‘div’, attrs = {‘class’: ‘IsZvec’}).
После получения всех элементов мы можем использовать .text, чтобы получить только текст, находящийся под этими элементами. Информация, которую мы ищем на веб-странице, может быть размещена в разных элементах, поэтому можно использовать инструменты инспектора, чтобы найти нужные элементы. Например, можно щелкнуть правой кнопкой мыши на веб-странице, выбрать "Inspect" и увидеть исходный код, как показано на рисунке ниже.
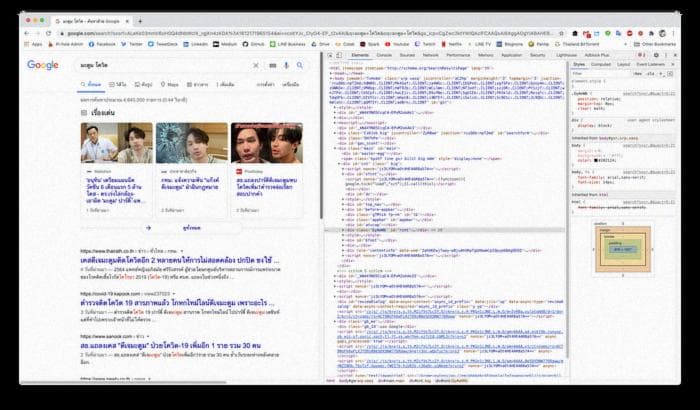
После получения всех необходимых данных их можно сохранить в список или в другую переменную, в зависимости от вашего выбора, или создать DataFrame для дальнейшего использования.
Заключение
Вот и заканчивается пример парсинга Google поиска, который можно считать базовым для парсинга веб-страниц. Если у вас есть интересные идеи для других форматов парсинга, не стесняйтесь попробовать и рассказать о своем опыте.
dataScienceLab/googleScraping.ipynb в ветке main · naenumtou/dataScienceLab
Все статистические модели / машинное обучение / компьютерное зрение / финансовые модели / NLP / техники Python / библиотеки...
github.com
Вы можете посмотреть Colab notebook на GitHub, указанном выше.