
Парсинг с использованием Selenium + Heroku + Telegram Bot (Часть 1)
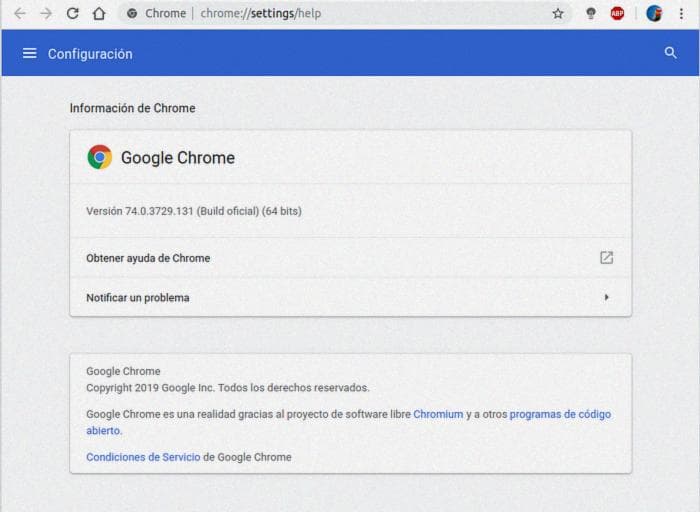
Table Of Content
- Введение (можно пропустить)
- Что такое парсер?
- Парсинг динамических веб-страниц с использованием Selenium и Python (начните здесь, если вы знаете, что такое парсер)
- Шаг 1: Установка Selenium
- Загрузки - ChromeDriver - WebDriver для Chrome
- WebDriver для Chrome
- Базовый код
- Анализ кода
- Запуск ChromeDriver с помощью Python selenium на Heroku
- Благодарим за ответ на вопрос на Stack Overflow! Пожалуйста, убедитесь, что вы отвечаете на вопрос. Предоставьте подробности и поделитесь...
- RNogales94/Selenium-Heroku-Python-POC
- Простой пример концепции парсера веб-страниц с использованием Selenium внутри приложения на Python и развернутого на Heroku...

Введение (можно пропустить)
Часто мы сталкиваемся с информацией, которая изменяется на некоторых веб-сайтах, и мы хотели бы получать персонализированные уведомления. Например, мы хотели бы получать оповещение, если определенная цена акции достигает определенной суммы, или если товар на Amazon снижается в цене...
В большинстве случаев такие ситуации можно предвидеть, и поставщики информации активируют для нас эти "напоминания", чтобы мы снова посетили их веб-сайт.
Но что делать, если мы хотим что-то более персонализированное или просто сами хотим предоставить эту функцию с помощью бота? Обычно есть два варианта для достижения этой цели, легкий и сложный, как обычно...
- Легкий: Существует API, которую предоставляет оригинальный поставщик данных. Например, мы хотим узнать погоду в нашем городе и получать уведомления, когда идет дождь и т.д. В этом случае нам просто нужно найти OpenWeatherMap и зарегистрироваться в их API, и мы можем легко подключить нашего бота к OpenWeatherMap, достаточно немного поискать в Google, так как этот пример очень распространен и часто встречается в учебниках среднего уровня.
- Сложный: Нет API (или она есть, но нам ее не дают). В этом случае нам нужно извлечь информацию, используя сам веб-сайт, притворяясь, что наш бот - это человек, который заходит на веб-сайт, что известно как "парсинг веб-страниц".
Что такое парсер?
Это программа, которая автоматически получает доступ к веб-странице и может считывать информацию на ней, а также нажимать на кнопки, заполнять формы и перемещаться по странице, как это делал бы человек.
Если веб-сайт небольшой, скорее всего у него нет механизмов против парсинга, таких как CAPTCHA (которые, кстати, являются аббревиатурой от "Completely Automated Public Turing test to tell Computers and Humans Apart" - полностью автоматизированный публичный тест Тьюринга для различения компьютеров и людей).
В случае наличия CAPTCHA у нас есть два варианта, снова легкий и сложный.
Легкий способ - сменить IP-адрес, чтобы наша система каждый раз получала доступ к сервису с другим IP-адресом и всегда получала данные.
Сложный способ - разгадать CAPTCHA, обычно это возможно с помощью системы искусственного интеллекта, основанной на сверточных нейронных сетях, так как большинство CAPTCHA состоят в классификации изображений.
Если есть CAPTCHA, скорее всего, "не стоит" парсить этот веб-сайт, и лучше запросить доступ к API, чтобы избежать многих технических проблем и, вероятно, не нарушать условия предоставления услуги.
При парсинге нужно учитывать, что целью является имитация поведения человека, поэтому не следует делать 300 запросов в секунду, так как немногие люди могут кликать на такой скорости с помощью мыши, и, следовательно, скорее всего, нас забанят.
При слишком большом количестве запросов в минуту мы также наносим вред владельцу веб-сайта, так как перегружаем сервер, и это может рассматриваться как атака отказа в обслуживании (DDoS).
Сказав это, мы можем приступить к делу, зная технические ограничения и последствия, которые могут возникнуть для поставщика услуг.
В этом примере мы извлечем ежедневные предложения с amazon.com и сможем просматривать их с помощью бота Telegram.
Веб-страница с ежедневными предложениями находится здесь: https://www.amazon.es/gp/goldbox?tag=wasubi0a-21
Параметр tag необязателен, но если вы его используете, вы можете получить часть комиссии от продаж, совершенных с использованием этой ссылки.
Если мы проанализируем JavaScript-код этой страницы, мы обнаружим, что веб-страница генерируется динамически, поэтому, если мы используем базовый модуль Python, такой как Beautiful Soup, для парсинга веб-страницы, мы не получим ничего полезного, так как мы не можем построить конечный HTML без движка JavaScript.
Именно это делает браузер: он загружает начальный HTML с указанного URL, если есть JavaScript, он интерпретирует его и создает DOM, который представляет веб-страницу в абстрактной форме внутри нашего браузера.
Парсинг динамических веб-страниц с использованием Selenium и Python (начните здесь, если вы знаете, что такое парсер)
Selenium - это инструмент для автоматического тестирования веб-страниц, обычно он очень полезен для фронтенд-разработчиков и специалистов по контролю качества.
Но мы можем использовать его на веб-страницах, которые не являются нашими, и автоматически переходить по этим страницам. Именно это мы собираемся сделать с помощью Amazon.
Шаг 1: Установка Selenium
Я буду использовать Chrome для парсера, хотя могу использовать и Firefox, я использую Chrome, потому что есть больше документации, хотя это действительно личное решение.
Selenium требует наличия установленного браузера, поэтому, если у вас нет Google Chrome, вам нужно его установить.
Вы должны узнать свою версию Chrome chrome://settings/help
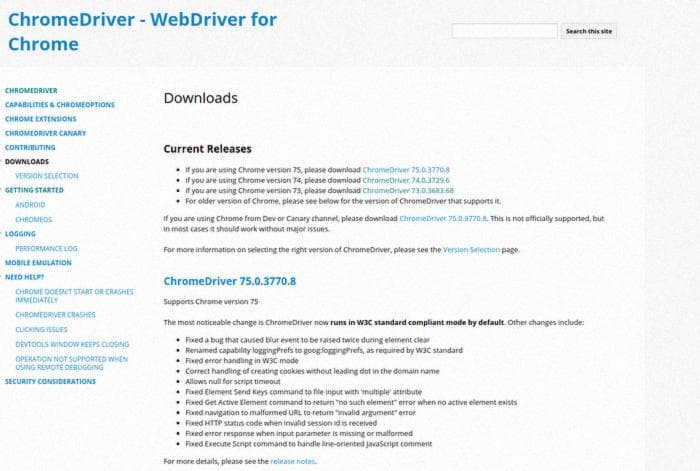
Загружаем ChromeDriver, совместимый с нашей версией Google Chrome:
Загрузки - ChromeDriver - WebDriver для Chrome
WebDriver для Chrome
WebDriver для Chrome ссылка
Теперь мы должны открыть консоль, чтобы установить Selenium в нашу среду Python.
$ pip install selenium
Базовый код
Вот шаблон кода, с которого вы можете начать
from selenium import webdriver
from selenium.common.exceptions import NoSuchElementException, WebDriverException
from selenium.webdriver.chrome.options import Options
import osCHROMEDRIVER_PATH = os.environ.get('CHROMEDRIVER_PATH', '/usr/local/bin/chromedriver')
GOOGLE_CHROME_BIN = os.environ.get('GOOGLE_CHROME_BIN', '/usr/bin/google-chrome')
options = Options()
options.binary_location = GOOGLE_CHROME_BIN
options.add_argument('--disable-gpu')
options.add_argument('--no-sandbox')
options.headless = Truedriver = webdriver.Chrome(executable_path=CHROMEDRIVER_PATH, chrome_options=options)# Парсинг
url = 'https://www.amazon.es/dp/B006CZ0LGA'driver.get(url)el = driver.find_element_by_id('priceblock_ourprice')print(el.text)Возможно, вы правильно установили Selenium, но все равно получаете эту ошибку:
FileNotFoundError: [Errno 2] No such file or directory: '/usr/local/bin/chromedriver': '/usr/local/bin/chromedriver'selenium.common.exceptions.WebDriverException: Message: 'chromedriver' executable needs to be in PATH. Please see [https://sites.google.com/a/chromium.org/chromedriver/home](https://sites.google.com/a/chromium.org/chromedriver/home)Это происходит потому, что у вас нет драйвера для вашего браузера Chrome в этом пути. Если вы его загрузили и не переместили, он должен находиться в папке "Загрузки". Вы также можете изменить путь в коде, чтобы он искал драйвер в другой папке, даже в "Загрузках", но это менее чистое решение.
Анализ кода
В коде мы создаем драйвер, то есть браузер, который мы будем использовать для парсинга Amazon. Опции выбраны таким образом, чтобы они работали на сервере без графического интерфейса, без GPU и с минимальными требованиями, как в случае с динами Heroku.
Способ загрузки chromedriver и google-chrome осуществляется через переменные среды, которые позволяют нам проводить тесты как локально, так и на Heroku при развертывании.
После создания драйвера мы будем использовать его для извлечения информации с конкретного веб-сайта, в данном случае с веб-сайта продукта Amazon, и извлекаем его цену.
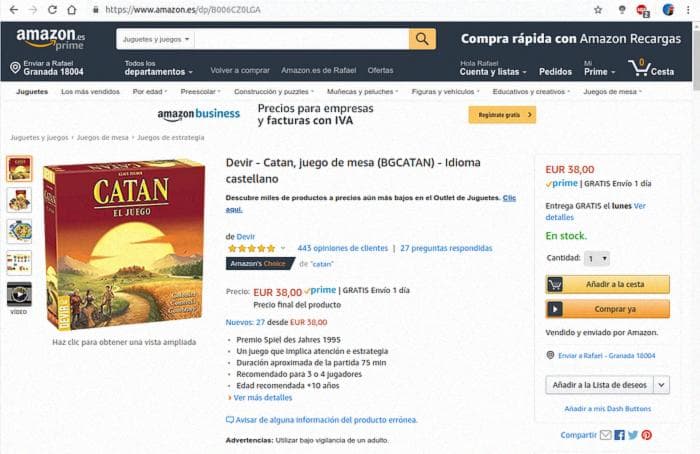
Это URL и то, что мы видим с помощью Chrome.
Если мы щелкнем правой кнопкой мыши на цене и выберем "Проверить элемент", мы сможем увидеть его идентификатор и затем найти элемент в DOM с помощью Selenium.

Поэтому мы ищем элемент, где находится цена, так:
el = driver.find_element_by_id('priceblock_ourprice')Вот ссылка на вопрос на StackOverflow, который может прояснить ситуацию.
Запуск ChromeDriver с помощью Python selenium на Heroku
Благодарим за ответ на вопрос на Stack Overflow! Пожалуйста, убедитесь, что вы отвечаете на вопрос. Предоставьте подробности и поделитесь...
stackoverflow.com
В следующей части мы рассмотрим, как развернуть парсер на Heroku и как подключить его к Telegram.
Здесь вы можете посмотреть мой исходный код.
RNogales94/Selenium-Heroku-Python-POC
Простой пример концепции парсера веб-страниц с использованием Selenium внутри приложения на Python и развернутого на Heroku...
github.com
Если вы хотите связаться со мной, вы можете сделать это через Telegram или LinkedIn, и мы можем обсудить ваш проект.
Вторая часть здесь https://planetachatbot.com/scraping-dinamico-con-selenium-heroku-telegram-bot-parte-2-f657ac030fb5


