
Парсинг с помощью Puppeteer
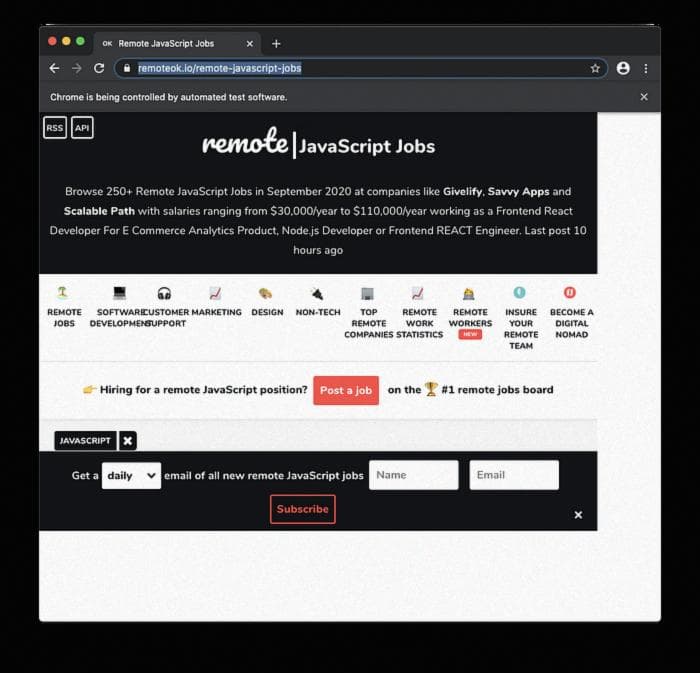
Table Of Content
- В этой статье мы создадим "Доску вакансий JavaScript", которая будет собирать удаленные вакансии для разработчиков JavaScript.
- Создайте парсер для вакансий JavaScript
- Установка Puppeteer
- Получение вакансий со страницы
- Сохранение вакансий в базе данных
- Создание приложения Node.js для визуализации вакансий
- Введение
- Установка
- Использование
- Вывод
В этой статье мы создадим "Доску вакансий JavaScript", которая будет собирать удаленные вакансии для разработчиков JavaScript.
Вот шаги для завершения нашего проекта:
Следует быть осторожным: я использую этот веб-сайт только в качестве примера. Я не рекомендую вам парсить его, потому что у него есть официальное API, если вы хотите использовать его данные. Это просто для объяснения того, как работает Puppeteer с веб-сайтом, который знают все, и чтобы показать вам, как вы можете использовать его на практике.
Поехали!
Создайте парсер для вакансий JavaScript
Мы собираемся парсить вакансии JavaScript с сайта remoteok.io, отличного сайта с удаленными вакансиями.
На сайте размещено много разных видов вакансий. Вакансии JavaScript перечислены под тегом "JavaScript" и, на момент написания, все они доступны на этой странице: https://remoteok.io/remote-javascript-jobs
Я сказал "на момент написания", потому что это важное понимание: сайт может измениться в любое время. Нам ничего не гарантировано. При парсинге любое изменение на сайте может привести к остановке нашего приложения. Это не API, которое является своего рода контрактом между двумя сторонами.
Из моего опыта следует, что парсинговые приложения требуют больше обслуживания. Но иногда у нас нет другого выбора для выполнения определенной задачи, поэтому они по-прежнему являются валидным инструментом в нашем распоряжении.
Установка Puppeteer
Давайте начнем с создания новой папки и запустим внутри нее следующую команду:
npm init -yЗатем установим Puppeteer, используя следующую команду:
npm install puppeteerТеперь создадим файл app.js. В начале файла подключим установленную нами библиотеку Puppeteer:
const puppeteer = require("puppeteer")Затем мы можем использовать метод launch() для создания экземпляра браузера:
;(async () => {
const browser = await puppeteer.launch({ headless: false })
})()Мы передали объект конфигурации { headless: false }, чтобы показать Chrome во время выполнения операций Puppeteer, чтобы мы могли видеть, что происходит. Это полезно при разработке приложения.
Затем мы можем использовать метод newPage() объекта browser, чтобы получить объект page, и вызвать метод goto() объекта page, чтобы загрузить страницу с вакансиями JavaScript:
const puppeteer = require('puppeteer');(async () => {
const browser = await puppeteer.launch()
const page = await browser.newPage()
await page.goto("https://remoteok.io/remote-javascript-jobs
")
})()Теперь запустите команду node app.js в терминале, и запустится экземпляр Chromium, загружая указанную нами страницу:
Получение вакансий со страницы
Теперь нам нужно найти способ получить информацию о вакансиях со страницы.
Для этого мы воспользуемся функцией page.evaluate(), которую предоставляет нам Puppeteer.
Внутри ее обратного вызова мы фактически переходим в браузер, чтобы использовать объект document, который теперь указывает на DOM страницы, хотя код будет выполняться в среде Node.js. Это некоторая магия, которую выполняет Puppeteer.
Внутри этой функции мы не можем ничего выводить в консоль, потому что это будет выводиться в консоль браузера, а не в терминал Node.js.
Что мы можем сделать, так это вернуть объект из этой функции, чтобы иметь к нему доступ как к значению, возвращаемому page.evaluate():
const puppeteer = require('puppeteer');(async () => {
const browser = await puppeteer.launch({ headless: false })
const page = await browser.newPage()
await page.goto('https://remoteok.io/remote-javascript-jobs') /* Выполняем JavaScript на странице */
const data = await page.evaluate(() => {
return ....что-то...
}) console.log(data)
await browser.close()
})()Внутри этой функции мы сначала создаем пустой массив, который мы заполним значениями, которые хотим вернуть.
Мы находим каждую вакансию, которая находится в элементе HTML tr с классом job, затем получаем данные из каждой вакансии с помощью querySelector() и getAttribute():
/* Выполняем JavaScript на странице */
const data = await page.evaluate(() => {
const list = []
const items = document.querySelectorAll("tr.job") for (const item of items) {
list.push({
company: item.querySelector(".company h3").innerHTML,
position: item.querySelector(".company h2").innerHTML,
link: "https://remoteok.io" + item.getAttribute("data-href"),
})
} return list
})Я нашел точные селекторы, которые нужно использовать, посмотрев на исходный код страницы с помощью инструментов разработчика браузера:

Вот полный исходный код:
const puppeteer = require("puppeteer");(async () => {
const browser = await puppeteer.launch({ headless: false })
const page = await browser.newPage()
await page.goto("https://remoteok.io/remote-javascript-jobs") /* Выполняем JavaScript на странице */
const data = await page.evaluate(() => {
const list = []
const items = document.querySelectorAll("tr.job") for (const item of items) {
list.push({
company: item.querySelector(".company h3").innerHTML,
position: item.querySelector(".company h2").innerHTML,
link: "https://remoteok.io" + item.getAttribute("data-href"),
})
} return list
}) console.log(data)
await browser.close()
})()Если вы запустите этот код, вы получите массив объектов, каждый из которых содержит информацию о вакансии:
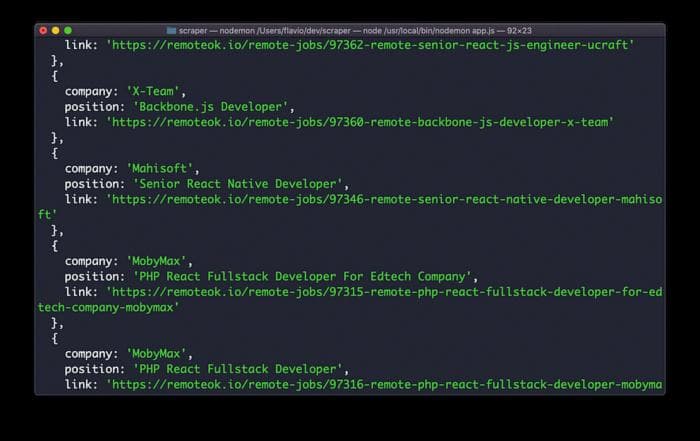
Сохранение вакансий в базе данных
Теперь мы готовы сохранить эти данные в локальной базе данных.
Мы будем запускать скрипт Puppeteer время от времени, сначала удаляя все сохраненные вакансии, а затем заполняя базу данных новыми найденными.
Мы будем использовать MongoDB. В терминале выполните следующую команду:
npm install mongodbЗатем в app.js добавьте эту логику для инициализации базы данных jobs и коллекции jobs внутри нее:
const puppeteer = require("puppeteer")
const mongo = require("mongodb").MongoClient
const url = "mongodb://localhost:27017"
let db, jobs
mongo.connect(
url,
{
useNewUrlParser: true,
useUnifiedTopology: true,
},
(err, client) => {
if (err) {
console.error(err)
return
}
db = client.db("jobs")
jobs = db.collection("jobs")
//....
}
)Теперь поместите код, который выполнял парсинг, в эту функцию, где есть комментарий //..... Это позволит коду выполняться после подключения к MongoDB:
const puppeteer = require("puppeteer")
const mongo = require("mongodb").MongoClient
const url = "mongodb://localhost:27017"
let db, jobs
mongo.connect(
url,
{
useNewUrlParser: true,
useUnifiedTopology: true,
},
(err, client) => {
if (err) {
console.error(err)
return
}
db = client.db("jobs")
jobs = db.collection("jobs")
;(async () => {
const browser = await puppeteer.launch({ headless: false })
const page = await browser.newPage()
await page.goto("https://remoteok.io/remote-javascript-jobs") /* Выполнение JavaScript на странице */
const data = await page.evaluate(() => {
const list = []
const items = document.querySelectorAll("tr.job")
for (const item of items) {
list.push({
company: item.querySelector(".company h3").innerHTML,
position: item.querySelector(".company h2").innerHTML,
link: "https://remoteok.io" + item.getAttribute("data-href"),
})
}
return list
})
console.log(data)
jobs.deleteMany({})
jobs.insertMany(data)
await browser.close()
})()
}
)В конце функции я добавил
jobs.deleteMany({})
jobs.insertMany(data)чтобы сначала очистить таблицу MongoDB, а затем вставить массив данных.
Теперь, если вы снова попробуете запустить node app.js и проверите содержимое базы данных MongoDB с помощью консоли терминала или приложения, такого как TablePlus, вы увидите, что данные присутствуют:
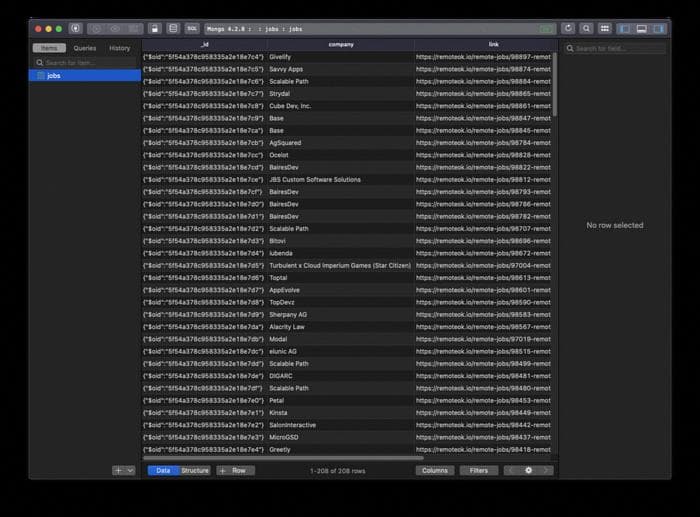
Отлично! Теперь мы можем настроить задание cron или любую другую автоматизацию для запуска этого приложения каждый день или каждые 6 часов, чтобы всегда иметь свежие данные.
Создание приложения Node.js для визуализации вакансий
Теперь нам нужен способ визуализации этих вакансий. Нам понадобится приложение.
Мы создадим приложение Node.js на основе Express и серверных шаблонов с использованием Pug.
Создайте новую папку и выполните в ней команду npm init -y.
Затем установите Express, MongoDB и Pug:
npm install express mongodb pugСначала мы инициализируем Express:
const express = require("express")
const path = require("path")
const app = express()
app.set("view engine", "pug")
app.set("views", path.join(__dirname, "."))
app.get("/", (req, res) => {
//...
})
app.listen(3000, () => console.log("Сервер готов"))Затем мы инициализируем MongoDB и получаем данные о вакансиях в массив jobs:
const express = require("express")
const path = require("path")
const app = express()
app.set("view engine", "pug")
app.set("views", path.join(__dirname, "."))
const mongo = require("mongodb").MongoClient
const url = "mongodb://localhost:27017"
let db, jobsCollection, jobs
mongo.connect(
url,
{
useNewUrlParser: true,
useUnifiedTopology: true,
},
(err, client) => {
if (err) {
console.error(err)
return
}
db = client.db("jobs")
jobsCollection = db.collection("jobs")
jobsCollection.find({}).toArray((err, data) => {
jobs = data
})
}
)
app.get("/", (req, res) => {
//...
})
app.listen(3000, () => console.log("Сервер готов"))Большая часть этого кода такая же, как код, который мы использовали в скрипте Puppeteer для вставки данных. Разница в том, что теперь мы используем find() для получения данных из базы данных:
jobsCollection.find({}).toArray((err, data) => {
jobs = data
})Наконец, мы отображаем шаблон Pug, когда пользователь переходит по пути /:
app.get("/", (req, res) => {
res.render("index", {
jobs,
})
})Вот полный файл app.js:
const express = require("express")
const path = require("path")
const app = express()
app.set("view engine", "pug")
app.set("views", path.join(__dirname, "."))
const mongo = require("mongodb").MongoClient
const url = "mongodb://localhost:27017"
let db, jobsCollection, jobs
mongo.connect(
url,
{
useNewUrlParser: true,
useUnifiedTopology: true,
},
(err, client) => {
if (err) {
console.error(err)
return
}
db = client.db("jobs")
jobsCollection = db.collection("jobs")
jobsCollection.find({}).toArray((err, data) => {
jobs = data
})
}
)
app.get("/", (req, res) => {
res.render("index", {
jobs,
})
})
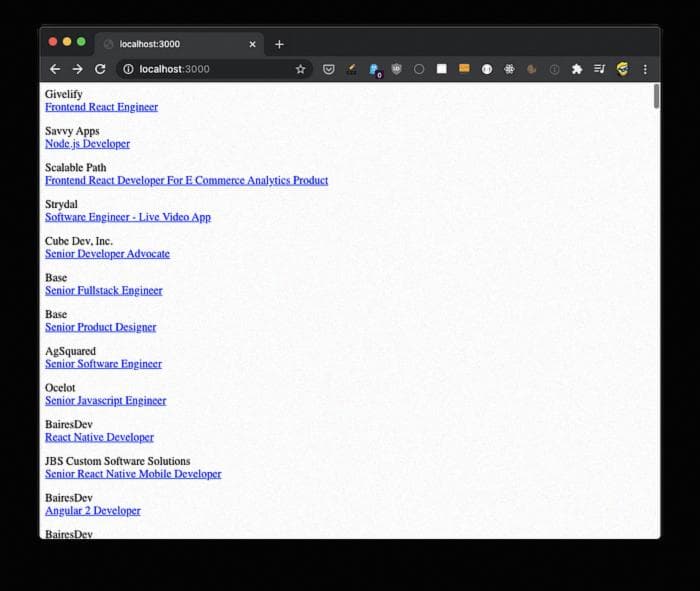
app.listen(3000, () => console.log("Сервер готов"))Файл index.pug, размещенный в той же папке, что и app.js, будет перебирать массив вакансий для вывода сохраненных деталей:
html
body
each job in jobs
p
| #{job.company}
br
a(href=`${job.link}`) #{job.position}Вот результат:
#Buka_Pitch
Введение
В данном проекте мы представляем парсер для извлечения информации с веб-страниц. Вместо использования скрэпинга, мы используем парсинг для получения данных. Наш парсер предоставляет удобный способ извлечения информации из HTML-кода в структурированном формате.
Установка
Для установки парсера, выполните следующие шаги:
- Установите Python, если он еще не установлен.
- Установите необходимые зависимости, выполнив команду
pip install parser. - Загрузите исходный код парсера с GitHub.
- Разархивируйте скачанный файл и перейдите в директорию проекта.
Использование
Для использования парсера, выполните следующие шаги:
- Импортируйте модуль парсера в свой код:
import parser. - Создайте экземпляр класса парсера:
p = parser.Parser(). - Используйте методы парсера для извлечения информации из HTML-кода.
Пример использования парсера:
html_code = "<html><body><h1>Пример страницы</h1><p>Это абзац текста.</p></body></html>"
parsed_data = p.parse(html_code)
print(parsed_data)Вывод
Наш парсер предоставляет простой и эффективный способ извлечения информации из HTML-кода. Он может быть использован для различных задач, таких как анализ веб-страниц, сбор данных и многое другое.