
Парсинг веб-сайта для поиска цен

Table Of Content
Проведено на платформе Zoom с 23 по 27 ноября.
Парсинг веб-сайта
Парсинг веб-сайта, также называемый "скрапингом", является техникой сбора данных в режиме реального времени с веб-страниц. Другими словами, это просто захват данных с сайта, их структурирование и сохранение.
Мой фокус в этом посте больше на практике, чем на теории, поэтому... приступим к делу.
Прежде всего, нам нужно установить две библиотеки Python, которые позволят нам легко работать с парсингом веб-сайтов:
- Selenium: Это инструмент, широко используемый в области тестирования для создания автоматизированных сценариев. Нам нужен этот инструмент, потому что контент, который мы хотим захватить с сайта, загружается динамически. С помощью Selenium мы сможем получить доступ к браузеру и имитировать навигацию по содержимому сайта.
- BeautifulSoup: Это пакет Python для анализа HTML- и XML-документов, он создает "дерево анализа" для страниц, которые можно использовать для извлечения данных из HTML.
После установки этих пакетов нам нужно решить, какой браузер мы будем использовать для доступа к сайту. В моем случае я выбрал использовать Google Chrome, поэтому я загрузил chromedriver и добавил его в переменную среды "Path". Теперь, наконец, мы готовы к нашему коду.
Давайте импортируем пакеты Python и создадим две переменные, одну для имени продукта и другую для URL-адреса сайта.
import requests
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import time
produto = "a21s"
url = "https://www.zoom.com.br/search?q="+produtoЗатем мы создадим экземпляр нашего веб-драйвера, который позволит нам навигировать по странице.
driver = webdriver.Chrome()
driver.get(url)Если вы правильно следовали всем шагам, при выполнении вашего кода вы должны перейти на эту страницу:
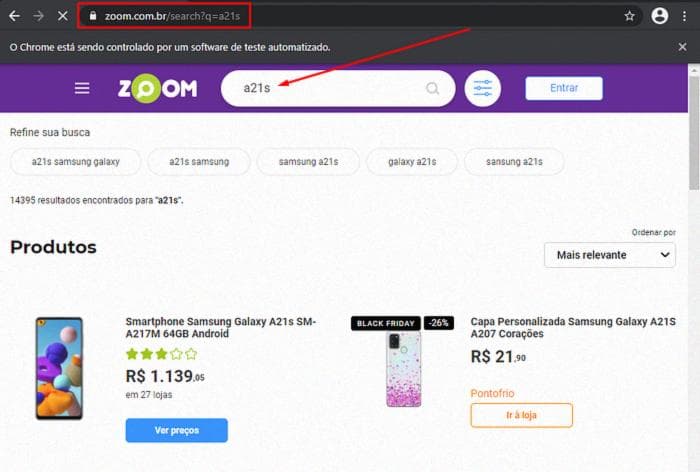
Чтобы взаимодействовать с содержимым страницы, мы будем использовать XPath (XML Path Language), которая является языком запросов для выбора элементов из XML/HTML-документа. Она поможет нам точно и быстро найти конкретный элемент в HTML-коде страницы. Если вы хотите лучше понять, что такое XPath, вы можете прочитать этот отличный пост, который рассказывает об этом.
Продолжая наш код... Давайте скопируем XPath кнопки "Посмотреть цены", чтобы с помощью Selenium мы могли нажать на нее и перейти к списку цен на этот продукт в магазинах.
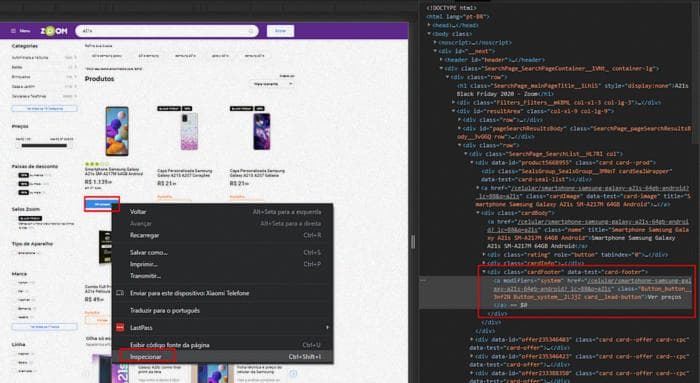
Просто скопируйте HTML-элемент в качестве XPath
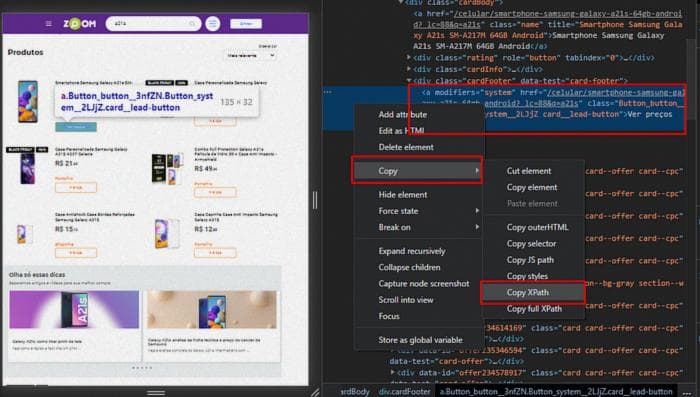
Мы будем использовать метод find_element веб-драйвера, передавая XPath элемента в качестве параметра, а затем выполним действие "click" на указанном XPath элементе.
driver.find_element_by_xpath(‘//*[@id=”resultArea”]/div[3]/div/div[1]/div[2]/div[3]/a’).click()Если вы снова выполните код, вы будете перенаправлены на страницу с перечнем цен на продукт в магазинах.

Теперь мы подходим к самой простой части, которая заключается в том, чтобы определить нужное содержимое, захватить его и сохранить в переменную.
element = driver.find_element_by_xpath('//*[@id="__next"]/div[1]/div[3]/div[2]/div/div/section[4]/div[2]/div[2]/div/ul')
html_content = element.get_attribute('outerHTML')В нашем случае, если мы внимательно рассмотрим содержимое, которое мы хотим, то увидим, что оно организовано в неупорядоченном списке HTML. Мы хотим получить элементы этого списка, которые и содержат информацию о цене, рассрочке, скидке и т.д.
soup = BeautifulSoup(html_content,'html.parser')
lista = soup.findAll(name='li')
for l in lista:
print('Samsung A21s : '+l.text+'\n')
driver.quit()Мы используем Beautiful Soup для "разбора" HTML, сохраненного в нашей переменной "html_content", и создаем список со всеми результатами элементов неупорядоченного списка HTML, затем мы перебираем список и печатаем результат. Наконец, мы просто закрываем наше окно браузера с помощью команды "driver.quit()". Вывод в консоли, если вы выполните код, должен быть похож на изображение ниже.
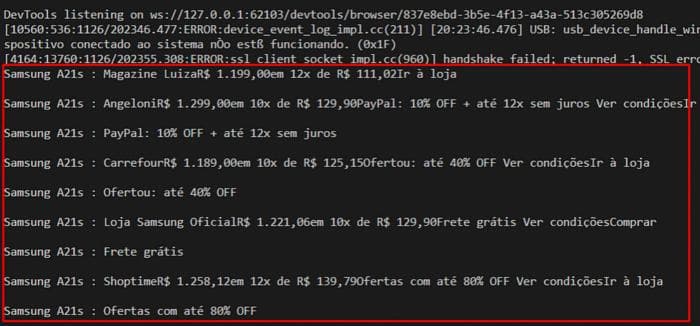
Если вы хотите, вы можете, например, автоматизировать сбор информации и сохранить ее в базе данных. В моем случае я автоматизировал сбор данных с помощью удивительного инструмента для автоматизации рабочих процессов, Apache Airflow, и сохранил собранные данные в файл CSV.
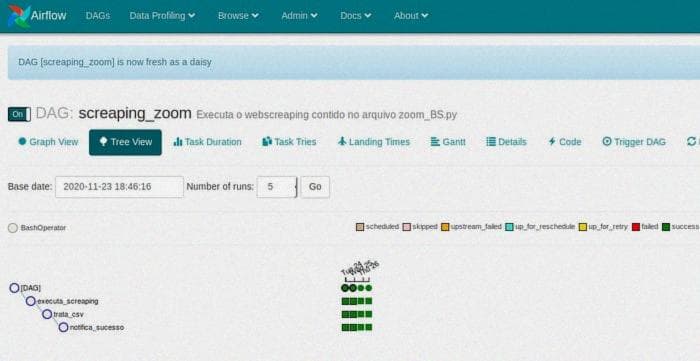
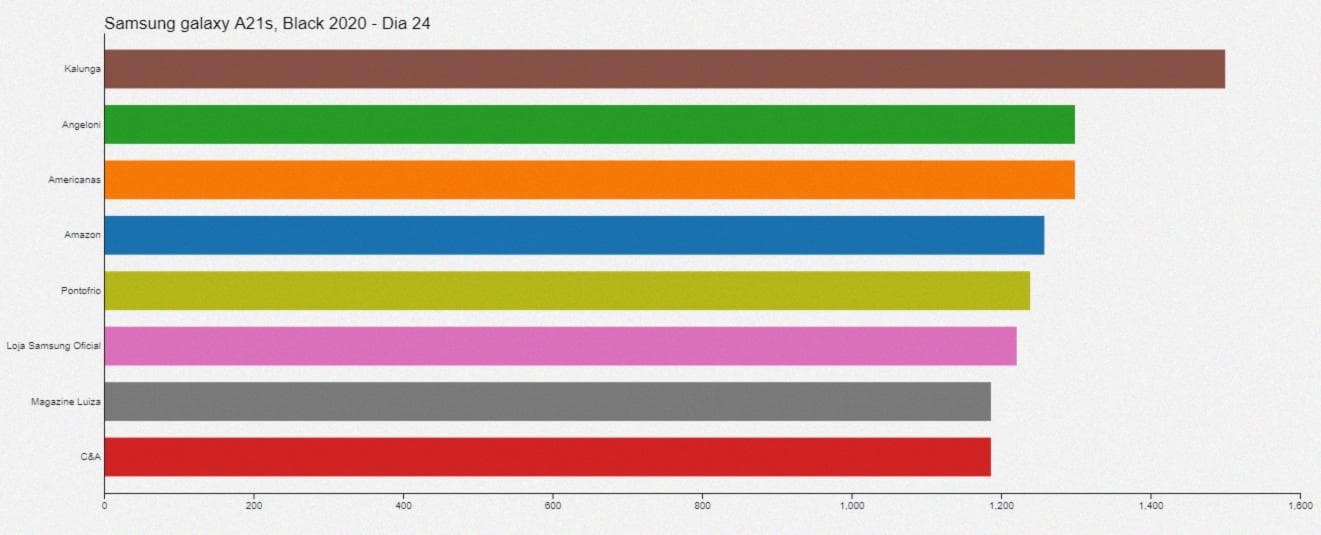
Затем, используя инструмент визуализации данных на JavaScript под названием D3, я создал визуализацию, которая показывает изменение цены смартфона во время Black Friday 2020 года.
Ссылка на полный код на GitLab: https://gitlab.com/thiago555sans/webscreaping_zoom/-/blob/master/Zoom.py
Ссылка на блокнот с кодом визуализации, созданной с помощью D3: https://observablehq.com/@thiagosantos/alteracao-de-precos