
Парсинг веб-страниц с использованием Python, Selenium и Pandas
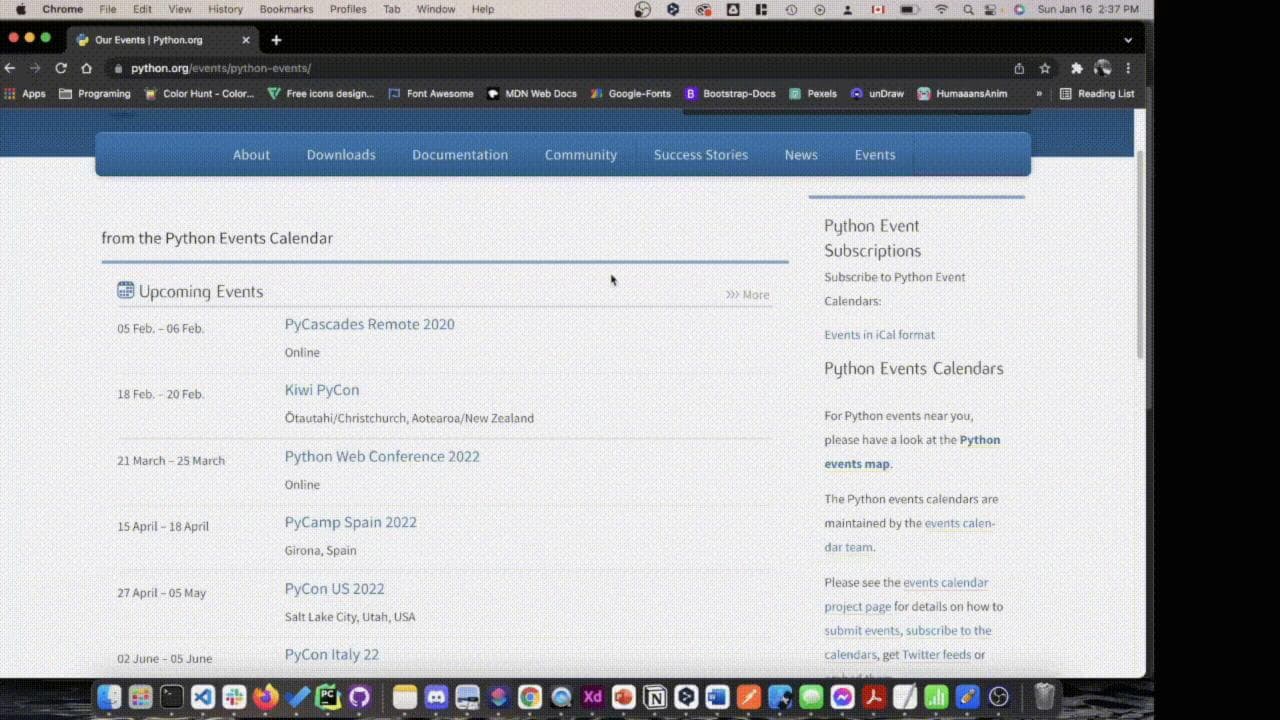
Table Of Content
- Этика парсинга веб-страниц:
- Требования:
- **Установка Python:**
- **Настройка Chrome и Chromedriver:**
- **Установка Pandas и Selenium:**
- **Цель:**
- **Решение:**
- драйвер, загруженный на шаге 3 и разархивированный на шаге 4 установки Chrome и Chromedriver.
- замените Chrome на ваш выбранный браузер
- Получение только предстоящих событий, а не пропущенных событий
- создание массива заголовков предстоящих событий
- создание массива ссылок на предстоящие события
- создание массива дат предстоящих событий
- создание DataFrame
- сохранение содержимого DataFrame в CSV-файл
- закрытие окна браузера
- **Заключение:**
- Что почитать дальше?
Привет всем, добро пожаловать в эту статью, где мы будем использовать Python для парсинга содержимого веб-страницы.
Этика парсинга веб-страниц:
Прежде всего, что такое парсинг веб-страниц? Парсинг веб-страниц относится к процессу использования программы (также известной как боты) для получения информации из HTML-страницы. Теперь, когда мы определили парсинг веб-страниц, возникает вопрос об этике этой практики: является ли парсинг веб-страниц законным?
Ответ на этот вопрос зависит от того, кого вы спросите. Использование программы для получения данных с веб-страницы аналогично ручному осмотру страницы в вашем браузере. С другой стороны, у вас может не быть разрешения владельца на получение этих данных. Я считаю, что лучше всего использовать API, чтобы избежать юридических конфликтов. Кроме того, Я НЕ РЕКОМЕНДУЮ парсить сайт, требующий аутентификации, такой как Facebook, Instagram ..., и мое окончательное рекомендация - не парсить веб-страницу слишком часто, так как это может привести к сбою сайта.
Теперь, когда мы обсудили этический аспект парсинга веб-страниц, мы можем продолжить, как это сделать.
Требования:
Установка Python:
Чтобы получить последнюю версию Python, перейдите на этот сайт.
Настройка Chrome и Chromedriver:
В этом руководстве я собираюсь использовать Chrome. Вы можете использовать любой браузер, если у вас есть правильные драйверы. Например, если вы хотите использовать Firefox, вам нужно получить Firefoxdriver.
Установка Pandas и Selenium:
Перейдите в папку по вашему усмотрению, откройте там VSCode, создайте файл main.py. Теперь откройте терминал (внутри VSCode) и введите следующие команды:
pip install pandas
pip install seleniumТеперь, когда у нас есть все необходимое, мы можем перейти к интересной части.
Цель:
Давайте спарсим официальный веб-сайт Python website. Вы можете увидеть раздел, который говорит о "Предстоящих событиях". Мы будем парсить эту веб-страницу, чтобы извлечь названия, даты и места событий и сохранить их в CSV-файл.
Решение:
Сначала откройте файл main.py и импортируйте pandas и selenium следующим образом:
import pandas as pd
from selenium import webdriverзатем мы свяжем загруженный ранее Chromedriver с selenium, используя следующий код:
# драйвер, загруженный на шаге 3 и разархивированный на шаге 4 установки Chrome и Chromedriver.chrome_webdriver_path = "/Users/abderraoufbenchoubane/Documents/medium_articles_repo/chromedriver"# замените Chrome на ваш выбранный браузерdriver = webdriver.Chrome(chrome_webdriver_path)Чтобы найти путь к драйверу, перейдите на левую панель в VSCode, щелкните правой кнопкой мыши и выберите опцию "копировать путь". (НЕ ИСПОЛЬЗУЙТЕ ОТНОСИТЕЛЬНЫЙ ПУТЬ)
Теперь откройте Chrome и щелкните правой кнопкой мыши на странице, выберите "Инспектировать". Наведите курсор на интересующие вас элементы, чтобы найти CSS-классы и имена тегов, которые их идентифицируют. (Я предполагаю, что читатель имеет базовое понимание HTML и CSS)
Чтобы извлечь заголовки, используйте следующий класс "event-title". Чтобы запросить ссылку на событие, используйте этот CSS-селектор “.event-title a”. Дата находится внутри элемента времени. Место проведения событий находится внутри div с классом “.event-location”.
Для выполнения запроса данных используйте следующий код:
# Получение только предстоящих событий, а не пропущенных событий
upcoming_event_div = driver.find_element_by_class_name("shrubbery")# создание массива заголовков предстоящих событий
events_titles = events_titles = [title.text for title in upcoming_event_div.find_elements_by_class_name("event-title")]# создание массива ссылок на предстоящие события
events_links = [link.get_attribute("href") for link in upcoming_event_div.find_elements_by_css_selector(".event-title a")]# создание массива дат предстоящих событий
events_dates = [date.text for date in upcoming_event_div.find_elements_by_tag_name("time")]$ создание массива мест проведения предстоящих событий
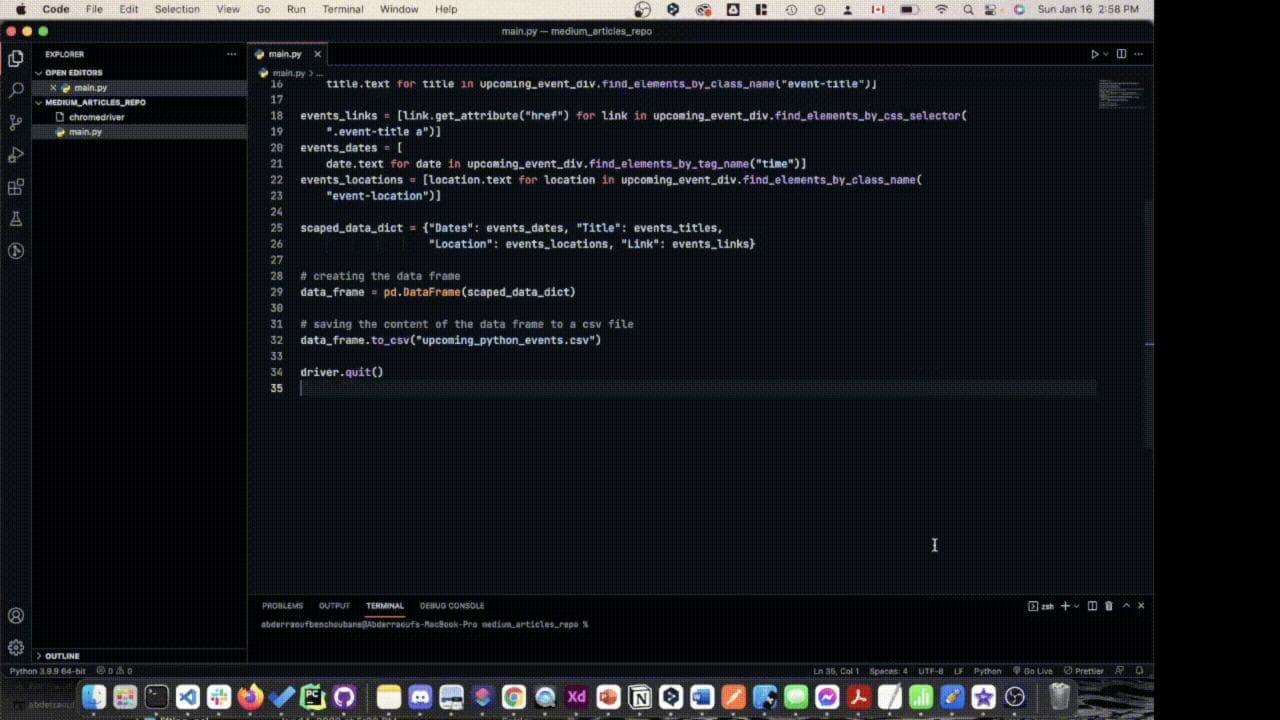
events_locations = [location.text for location in upcoming_event_div.find_elements_by_class_name("event-location")]Наконец, теперь, когда мы получили информацию с веб-страницы, мы можем использовать DataFrame Pandas для экспорта в CSV. Ниже приведен код, который создает CSV-файл из DataFrame.
scaped_data_dict = {"Dates": events_dates, "Title": events_titles,"Location": events_locations, "Link": events_links}# создание DataFrame
data_frame = pd.DataFrame(scaped_data_dict)# сохранение содержимого DataFrame в CSV-файл
data_frame.to_csv("upcoming_python_events.csv")# закрытие окна браузера
driver.quit()чтобы запустить скрипт, откройте окно терминала в VSCode и введите
python main.pyи вот у вас есть CSV-файл с названием "upcoming_python_events.csv", который содержит все предстоящие события.
Заключение:
В этой статье мы обсудили этику парсинга веб-страниц и выполнили простой пример. Надеюсь, вам понравился учебник. Если да, пожалуйста, подумайте о том, чтобы поставить лайк и подписаться на мою ленту.
Полный код можно найти здесь.