
Парсинг веб-страниц с использованием scrapy и JSON API

Научитесь парсить данные о вакансиях на monster.com с помощью scrapy.
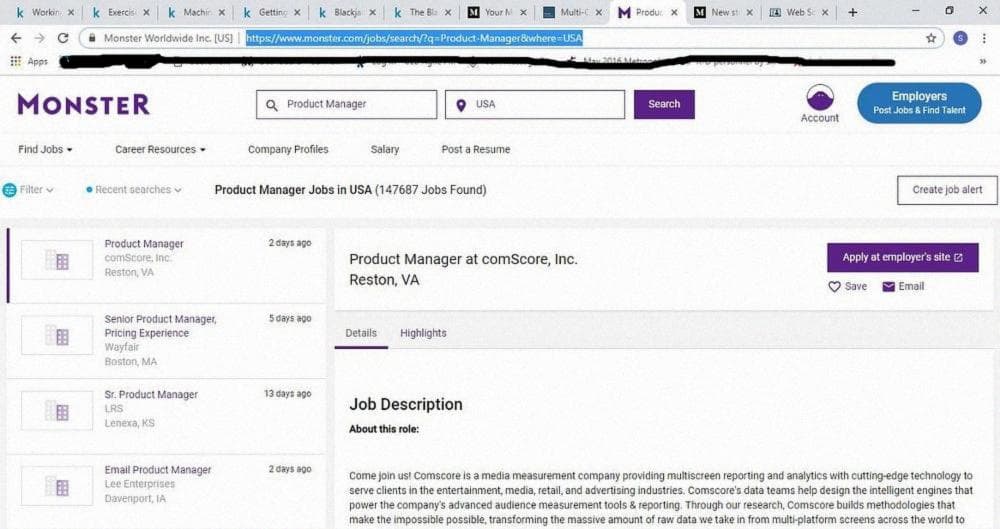
Сегодня мы будем парсить monster.com с помощью scrapy и JSON API. Мы будем использовать "Product Manager" в качестве названия вакансии и "USA" в качестве местоположения.
В этом упражнении мы будем использовать Python с scrapy и BeautifulSoup. Откройте терминал, я использую Anaconda Prompt на Windows. Перейдите в нужную директорию. Как только вы там, введите следующую команду в терминале:
scrapy startproject monster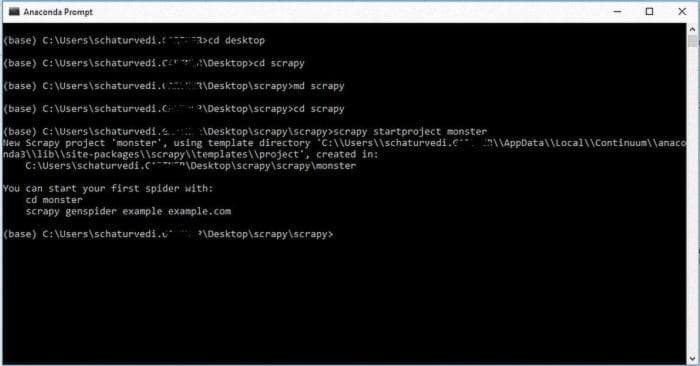
scrapy genspider monster-spider monster.comВаш паук создан!! Теперь перейдите в директорию scrapy/monster/monster/spiders. Откройте файл monster-spider.py в вашем любимом редакторе, который даст вам базовый шаблон паука. Я использую Visual Studio Code в качестве редактора.
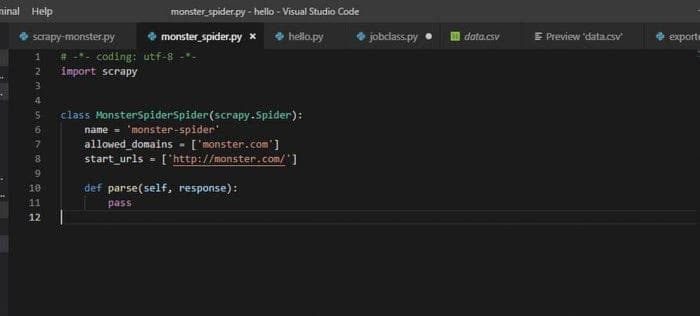
Теперь давайте попробуем базовый паук. Перейдите в терминал и введите:
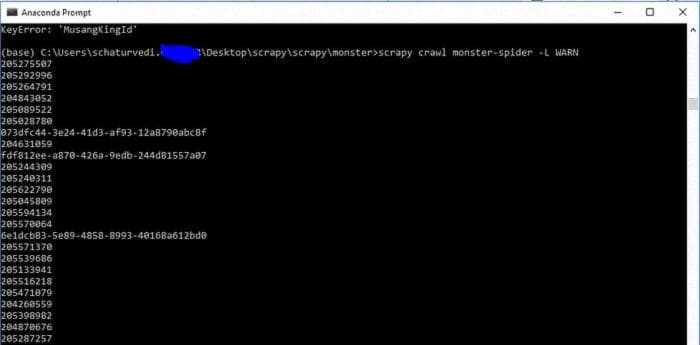
scrapy crawl monster-spider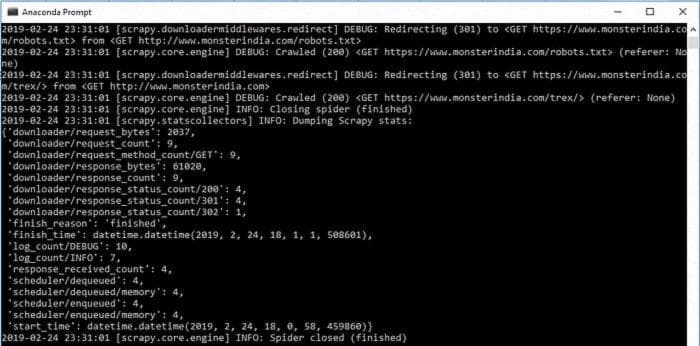
Мы можем использовать -L WARN, чтобы убрать все отладочные сообщения
scrapy crawl monster-spider -L WARNВывод будет примерно таким, как на изображении выше. Мы видим, что наш паук перенаправляется на monster.com.
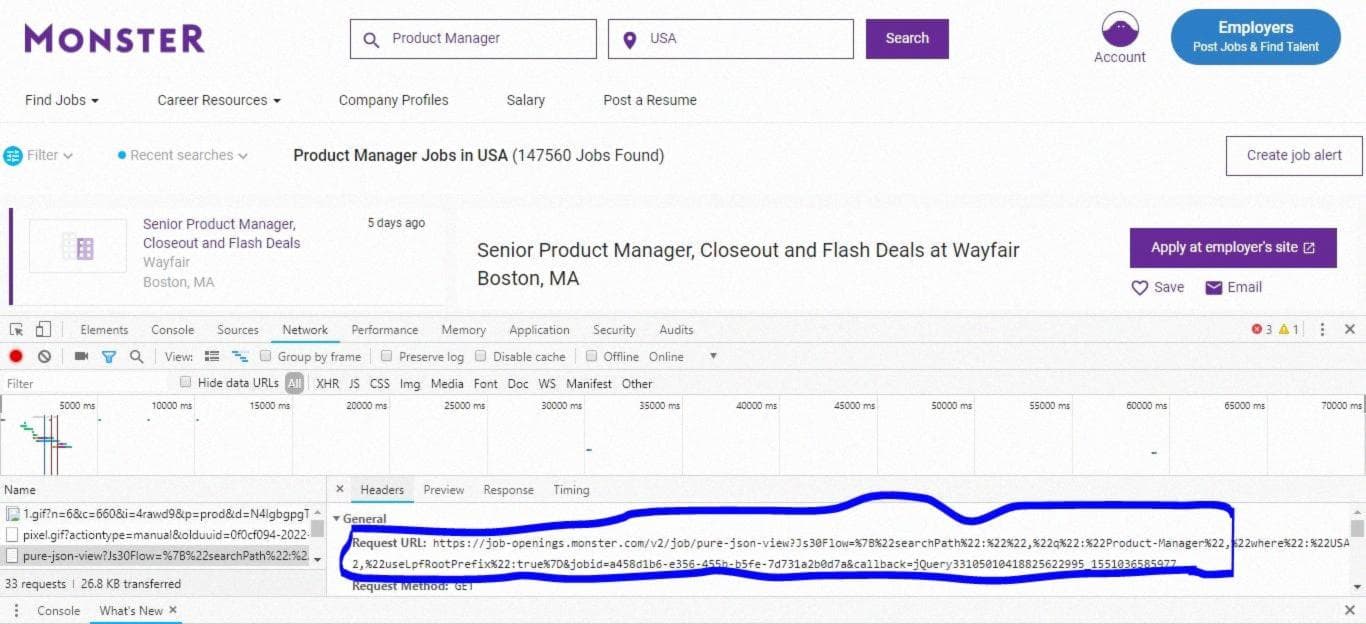
Теперь давайте перейдем на веб-сайт monster и выполним поиск вакансий Product Manager в США. Мы видим, что URL https://www.monster.com/jobs/search/?q=Product-Manager&where=USA&stpage=1&page=6&jobid=a0d751b0-a2d4-4ce4-9d1a-85ee2a2cba9b и https://www.monster.com/jobs/search/?q=Product-Manager&where=USA приводят нас на одну и ту же страницу. Мы используем этот URL - https://www.monster.com/jobs/search/?q=Product-Manager&where=USA при инспектировании (Ctrl +Shift+I, в Google Chrome(Windows)) веб-сайта. Прокрутите вниз и нажмите на "Load more jobs" и проверьте вкладку Network. См. иллюстрации ниже для справки.
Мы пытаемся найти шаблон в URL, чтобы применить его для итераций по нескольким страницам. Как вы увидите ниже, мы найдем URL, заканчивающийся на page =2, что означает, что номер страницы равен 2.
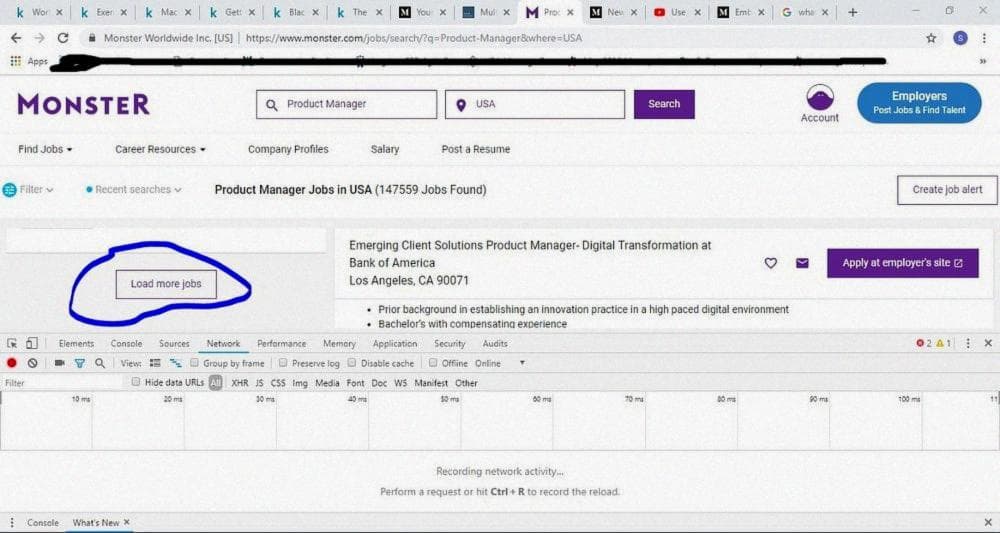
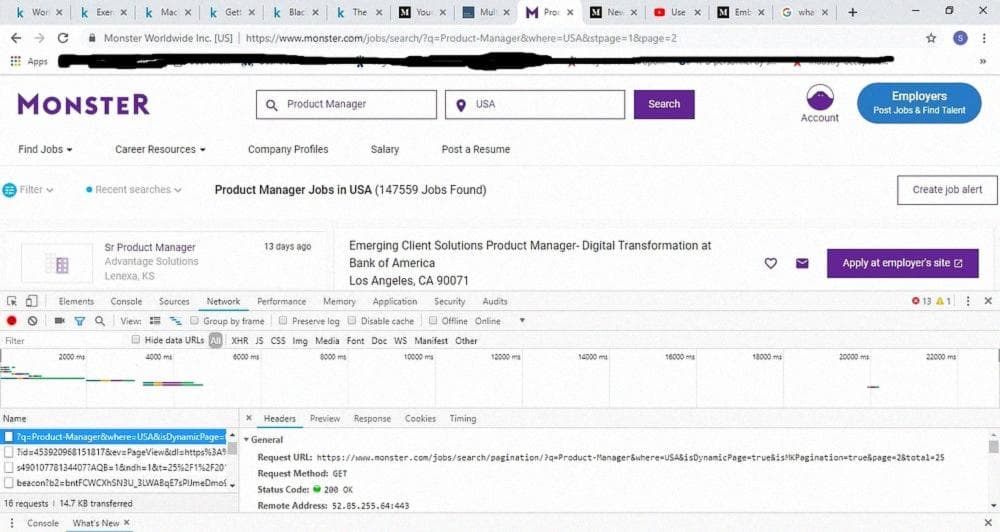
Теперь мы возьмем Request URL из вкладки Headers и вставим его в качестве стартового URL в наш паук, чтобы увидеть, что мы получим.
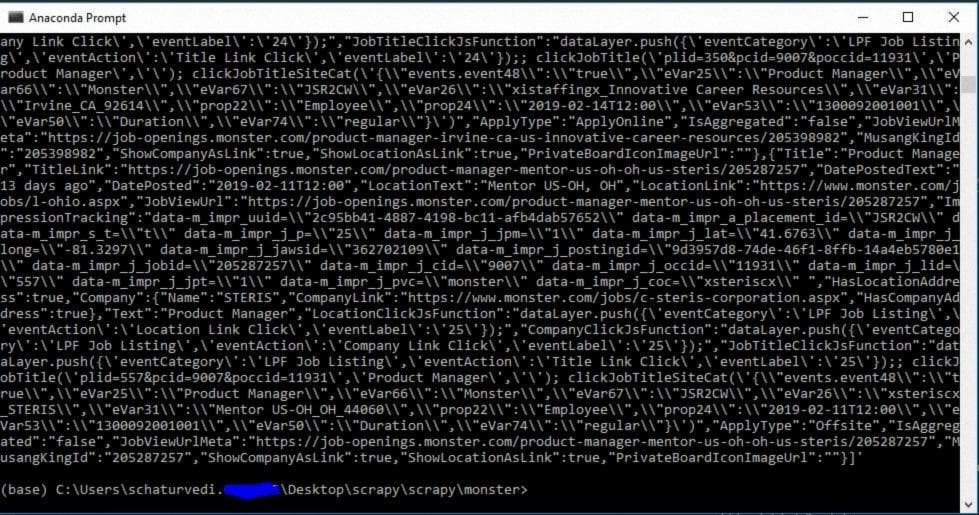
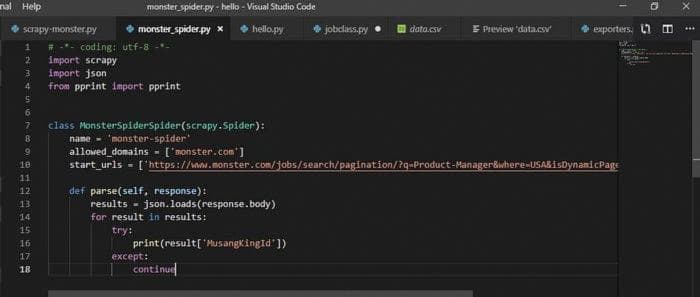
Как видите, вывод представляет собой данные в формате JSON. Мы импортируем pprint и json, чтобы сделать его более читабельным.
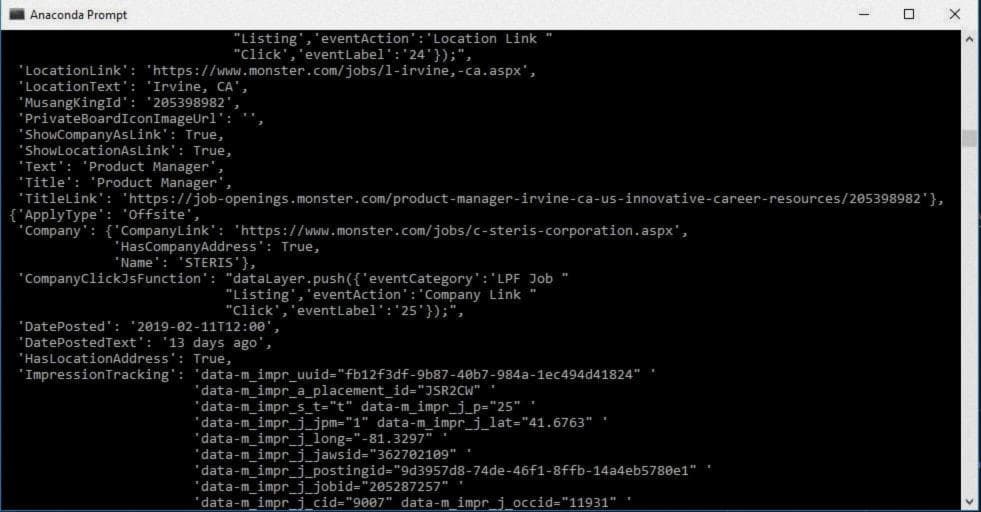
Если вы просмотрите вывод, вы найдете много интересных вещей, таких как Title, JobViewUrl и т.д. Мне интересно, что произойдет, если я попытаюсь открыть любой JobViewUrl в браузере. Давайте проверим это. И, конечно же, он открывает ссылку на работу на отдельной странице.
Давайте попробуем что-то еще. Перейдите по URL https://www.monster.com/jobs/search/?q=Product-Manager&where=USA** **и нажмите на вакансии в левой панели и посмотрите, что появляется во вкладке Network.
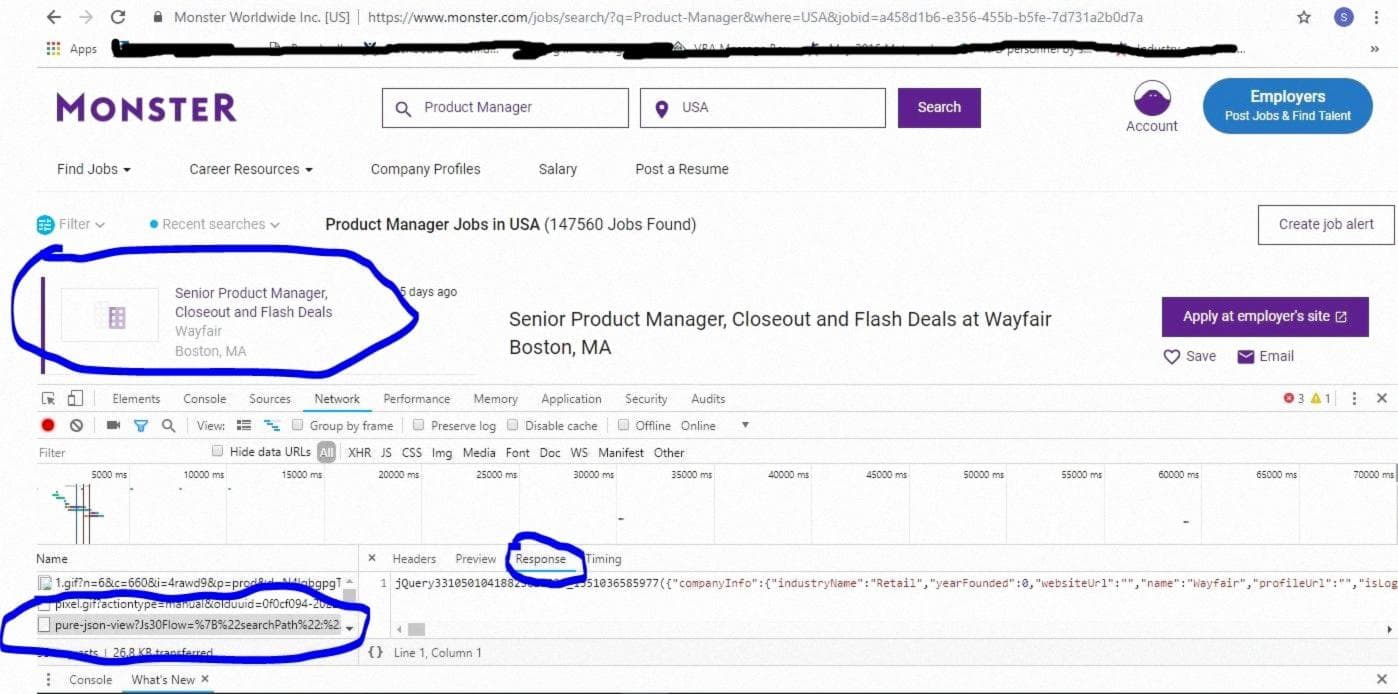
Мы получаем это, когда нажимаем на конкретное объявление о вакансии. Как мы увидим ниже, каждое объявление о вакансии содержит данные в формате JSON.
Если вы ищете какой-то текст из описания вакансии, он появится во вкладке Response. Это показывает, что мы можем получить нужный вывод из Request URL во вкладке Headers в формате JSON.
Но когда вы извлекаете URL, вы обнаруживаете, что он слишком сложный. Взгляните на него.
Ссылка выше сложна с таким количеством компонентов. Посмотрим, можем ли мы что-то сделать с этим.
[**https://job-openings.monster.com/v2/job/pure-json-view?Js30Flow=%7B%22searchPath%22:%22%22,%22q%22:%22Product-Manager%22,%22where%22:%22USA%22,%22useLpfRootPrefix%22:true%7D&jobid=205603967&callback=jQuery33105010418825622995_1551036585977**](https://job-openings.monster.com/v2/job/pure-json-view?Js30Flow=%7B%22searchPath%22%3A%22%22%2C%22q%22%3A%22Product-Manager%22%2C%22where%22%3A%22USA%22%2C%22useLpfRootPrefix%22%3Atrue%7D&jobid=205603967&callback=jQuery33105010418825622995_1551036585977)Посмотрим, что произойдет, если мы включим только jobid в ссылку и удалим все остальное, как показано ниже:
[**https://job-openings.monster.com/v2/job/pure-json-view?jobid=205603967**](https://job-openings.monster.com/v2/job/pure-json-view?jobid=205603967)
Отлично! Если вы ищете что-то из описания вакансии (через которое мы получили ссылку), вы найдете это в этом JSON-кодированном выводе.
Теперь, если мы обратимся к выводу, который мы получили в начале, импортируя json и pprint, мы можем ясно видеть, что JobID представлен ключом MusangKingID. Проанализируйте вывод и попробуйте понять, что означает каждый элемент. Например, Title относится к Job Title, JobViewUrl относится к URL этой конкретной вакансии. В разделе Company вы найдете URL компании и название компании.
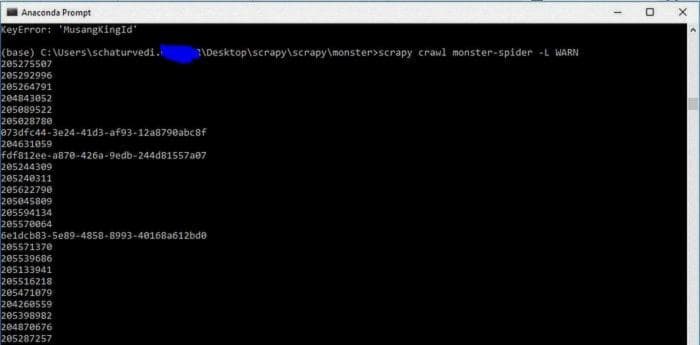
Таким образом, вышеуказанный вывод дает нам JobID для 2 страниц, так как стартовый URL установлен на 2 страницы на данный момент. Если мы изменяем его на 50 страниц, мы получим JobID для до 50 страниц. Вы можете видеть, что мы использовали здесь операторы try и except для обработки исключений.
Давайте посмотрим, что у нас есть на данный момент
[**https://www.monster.com/jobs/search/pagination/?q=Product-Manager&where=USA&isDynamicPage=true&isMKPagination=true&page=2**](https://www.monster.com/jobs/search/pagination/?q=Product-Manager&where=USA&isDynamicPage=true&isMKPagination=true&page=2)- У нас есть начальный URL для каждой работы в формате JSON. Все, что нам нужно, это идентификаторы работы.
[**https://job-openings.monster.com/v2/job/pure-json-view?jobid=**](https://job-openings.monster.com/v2/job/pure-json-view?jobid=205603967)- У нас есть идентификаторы работы, которые мы извлекли из начального URL в пункте 1.
Следующие шаги
Давайте красиво оформим наши данные в формате JSON, чтобы они были читаемыми. Я использую JSON Formatter & Validator для этого. Скопируйте все ваши данные и вставьте их в пустое поле, затем нажмите на кнопку "Process". Вуаля!

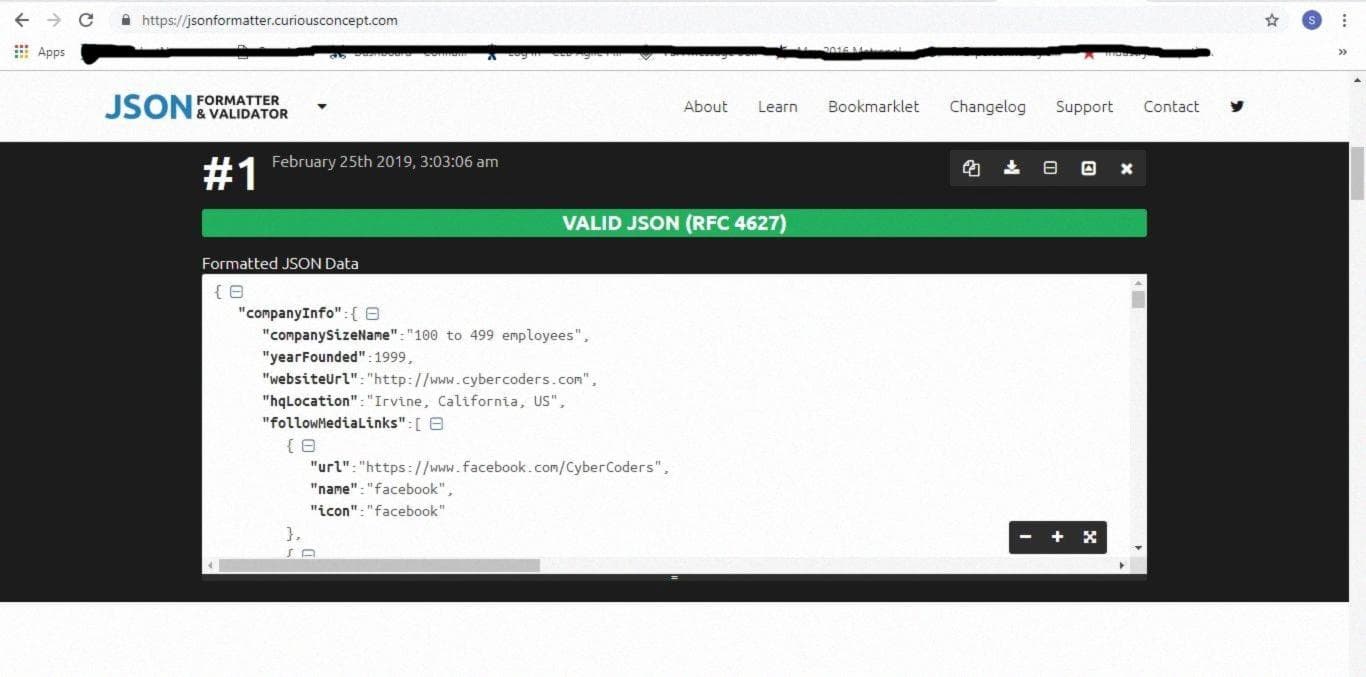
Вы можете видеть, что изображение справа гораздо более читаемо, чем исходные данные. Выберите атрибуты, которые вы хотите извлечь, такие как название компании, местоположение, описание работы, размер компании и т. д.
В приведенном выше коде мы извлекаем JobID, Title, Location, Company Info, Job Category, Job Description и т. д. Результат будет следующим:
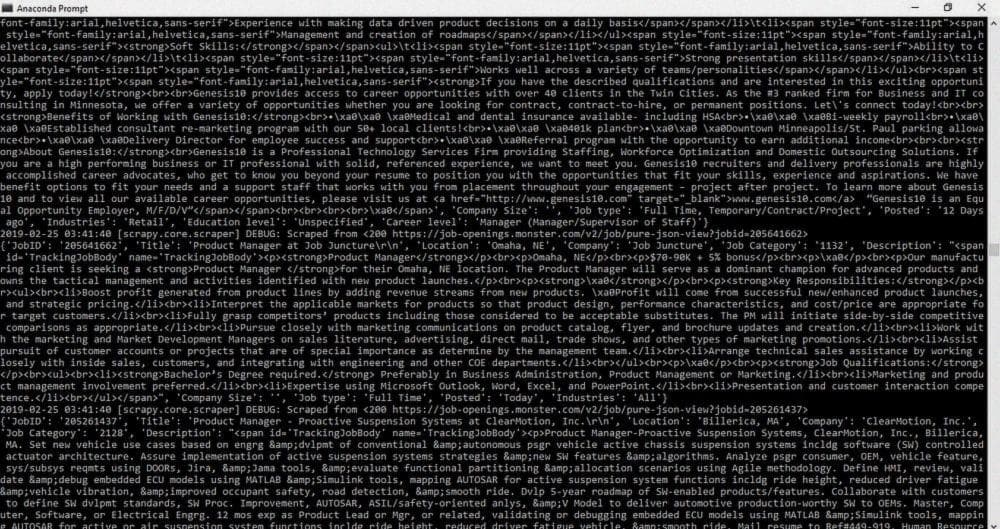
Если вы присмотритесь, вы увидите все выбранные атрибуты со своими значениями. Однако описание работы все еще находится в формате HTML и его трудно прочитать. Мы будем использовать BeautifulSoup, чтобы преобразовать этот HTML в читаемый формат. Следуйте этой ссылке, BeautifulSoup Grab Visible Webpage Text — Stack Overflow.
Наконец, в командной строке введите:
scrapy crawl monster-spider -L WARN -o monster.csvМы получим файл CSV с названием monster.csv, который будет выглядеть так:
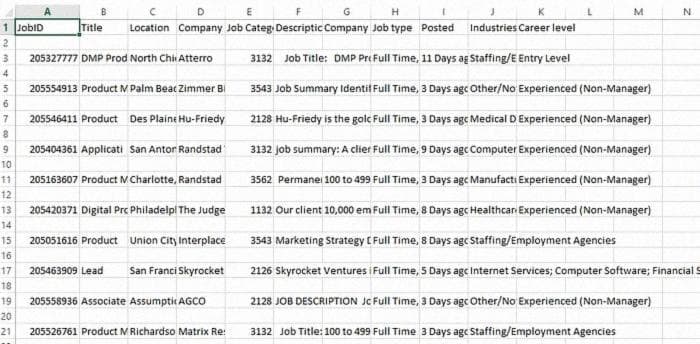
По умолчанию в Windows происходит следующее. Каждая строка сопровождается пустой строкой. Чтобы исправить это, обратитесь к этой ссылке или выполните следующие шаги:
Проверьте код ниже для setting.py и exporters.py:
# setting.py
FEED_EXPORTERS = {
'csv': 'myproject.exporters.CsvCustomSeperator'
}
# exporters.py
from scrapy.exporters import CsvItemExporter
class CsvCustomSeperator(CsvItemExporter):
def __init__(self, *args, **kwargs):
kwargs['delimiter'] = ';'
super(CsvCustomSeperator, self).__init__(*args, **kwargs)После выполнения этих шагов проверьте вывод еще раз. Он будет выглядеть так!
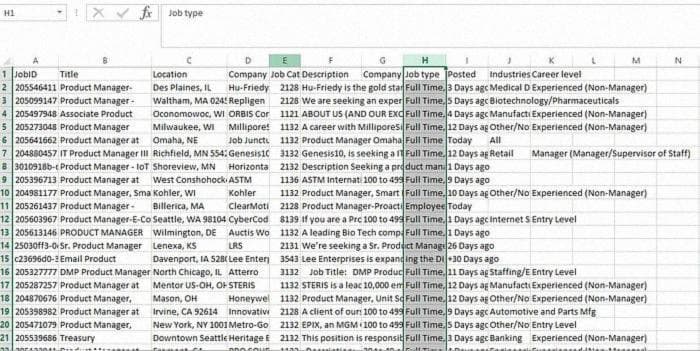
Наконец, мы закончили! Надеюсь, это было полезно и понятно. Я новичок в этом деле и буду рад любым предложениям и отзывам. Спасибо!