
Запланированный парсинг веб-сайта с помощью Django и Heroku
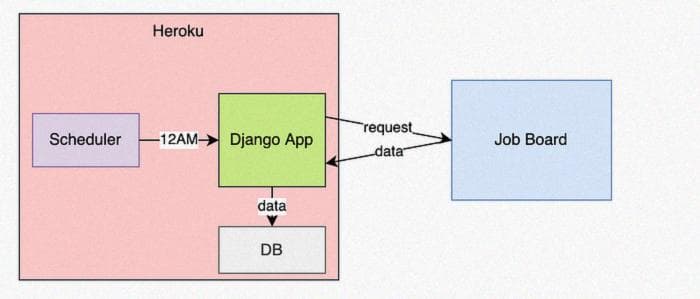
Создание приложения Django, которое ежедневно парсит доску вакансий
Мы часто нуждаемся в большом количестве обучающих данных для машинного обучения, и парсинг веб-сайтов может быть способом их получения.
Но в прошлом у меня была компания, в которой я очень хотел работать. У них не было вакансий по данным на тот момент, но как только они появятся, я хотел подать заявку.
Решение? Ежедневно парсить их доску вакансий, чтобы я получал уведомление о каждой новой вакансии.
Давайте создадим простое приложение Django, развернем его на Heroku и будем ежедневно парсить доску вакансий.
Настройка приложения
Создайте каталог для приложения и перейдите в него с помощью команды cd.
mkdir jobs && cd jobsОткройте его в выбранном вами редакторе кода. Я использую Sublime.
Создайте и запустите виртуальное окружение, а затем установите необходимые пакеты.
python -m venv env
source env/bin/activate
pip3 install django psycopg2 django-heroku bs4 gunicornСоздайте проект (веб-приложение Django).
django-admin startproject jobsПерейдите в каталог проекта и создайте приложение для парсинга.
cd jobs
django-admin startapp parsingСоздание модели Job
Нам понадобится определить только одну модель в этом приложении - модель Job. Она представляет собой собранные нами вакансии.
Перепишите /parsing/models.py следующим образом.
from django.db import models
from django.utils import timezone
class Job(models.Model):
url = models.CharField(max_length=250, unique=True)
title = models.CharField(max_length=250)
location = models.CharField(max_length=250)
created_date = models.DateTimeField(default=timezone.now)
def __str__(self):
return self.title
class Meta:
ordering = ['title']
class Admin:
passЗарегистрируйте свою модель в /parsing/admin.py. Это позволит нам просматривать записи в стандартной панели администратора Django (о ней мы поговорим позже).
from parsing.models import Job
admin.site.register(Job)Добавьте parsing в установленные приложения в /jobs/settings.py.
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'parsing'
]Настройка базы данных
Настройте базу данных. Я предпочитаю использовать postgres, поэтому мы будем использовать его.
На данном этапе убедитесь, что вы уже установили postgres на своем Mac с помощью brew и запустили его (это выходит за рамки данной статьи).
Создайте базу данных для этого проекта в командной строке. Вы можете открыть консоль postgres с помощью следующей команды.
psql -d template1Создайте пользователя и базу данных, затем выйдите.
create user django_user;
create database django_jobs owner django_user;
\qВ файле /jobs/settings.py обновите DATABASES. В других фреймворках вы захотели бы указать их специально для среды разработки, но здесь мы не будем об этом беспокоиться. В любом случае это будет работать на Heroku (мы скоро дойдем до этого).
Обратите внимание, что это имена пользователя и базы данных, которые мы создали выше.
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.postgresql_psycopg2',
'NAME': 'django_jobs',
'USER': 'django_user',
'HOST': '',
'PORT': ''
}
}Создайте миграции и выполните миграцию базы данных из командной строки.
python manage.py makemigrations
python manage.py migrateЭто создаст таблицу с названием scraping_job. Это соглашение пространства имен Django, потому что она принадлежит приложению scraping.
Теперь создайте суперпользователя и установите ему пароль в командной строке.
python manage.py createsuperuser --email admin@example.com --username adminТестирование текущего приложения
Мы уже проделали некоторую работу, но не знаем, работает ли что-нибудь. Давайте протестируем его, прежде чем продолжать.
В командной строке выполните следующую команду:
python manage.py runserverЗатем перейдите по адресу http://127.0.0.1:8000/admin в вашем браузере. Войдите в систему с помощью только что созданного суперпользователя.
После входа в систему нажмите на "jobs" в разделе "scraping", затем на "add job" в правом верхнем углу. Теперь заполните некоторую выдуманную информацию и нажмите "save". Если вы видите созданную вами задачу, значит, все работает до этого момента!
Пользовательские команды django-admin
Мы собираемся настроить пользовательскую команду django-admin, которая будет парсить доску вакансий. Это то, что мы будем автоматически планировать на уровне инфраструктуры для автоматизации парсинга.
Внутри модуля /scraping создайте каталог /management, а внутри /management создайте каталог /commands. Затем создайте 2 файла Python: _private.py и scrape.py в /commands.

Вставьте этот код в файл scrape.py.
from django.core.management.base import BaseCommand
from urllib.request import urlopen
from bs4 import BeautifulSoup
import json
from scraping.models import Job
class Command(BaseCommand):
help = "collect jobs"
def handle(self, *args, **options):
html = urlopen('https://jobs.lever.co/opencare')
soup = BeautifulSoup(html, 'html.parser')
postings = soup.find_all("div", class_="posting")
for p in postings:
url = p.find('a', class_='posting-btn-submit')['href']
title = p.find('h5').text
location = p.find('span', class_='sort-by-location').text
try:
Job.objects.create(
url=url,
title=title,
location=location
)
print('%s added' % (title,))
except:
print('%s already exists' % (title,))
self.stdout.write('job complete')Размещение кода в такой структуре каталогов, а затем определение класса Command с функцией handle говорит django, что это пользовательская команда django-admin.
Здесь мы используем библиотеку Beautiful Soup для парсинга доски вакансий Lever, а затем сохраняем ее в нашей базе данных. У меня нет отношения к этой компании, но я выбрал доску вакансий для фантастической компании Opencare - вы можете подать заявку, если они что-то разместят!
Теперь вы можете запустить эту команду из командной строки следующим образом:
python manage.py scrapeИ вы увидите этот вывод:

Запустите его снова и вы увидите это:

Это происходит потому, что мы предотвращаем добавление дублирующихся записей о вакансиях в коде scrape.py выше.
Если у вас настроена программа администрирования базы данных (например, dbeaver), вы также можете просматривать строки в вашей базе данных. Мы не будем вдаваться в это здесь, но это должно выглядеть примерно так:

Развертывание в продакшн
Теперь давайте развернем это на Heroku.
Заморозьте ваши зависимости, чтобы Heroku знал, что установить при развертывании.
pip3 freeze > requirements.txtВ командной строке выполните nano .gitignore и добавьте следующее.
.DS_Store
jobs/__pycache__
scraping/__pycache__Затем ctrl+x, y, enter для сохранения и закрытия (на Mac). Это предотвратит развертывание ненужных файлов.
Создайте файл с названием Procfile в корневой папке и вставьте следующее внутрь. Это сообщает Heroku запустить веб-дино и выполнить вторую команду для миграции базы данных.
web: gunicorn jobs.wsgi
release: python manage.py migrateСтруктура файлов будет выглядеть так.

Убедитесь, что у вас есть учетная запись [Heroku](http://heroku create flask-ml-api-123), затем выполните вход с помощью heroku login в командной строке.
Создайте приложение с любым именем, которое вам нравится. Но оно должно быть уникальным среди всех приложений на Heroku. Я использовал heroku create django-scraper-879, где имя приложения - django-scraper-879. Но вам нужно выбрать свое собственное имя.
Теперь добавьте эти строки в самый конец файла settings.py. heroku_django заботится о некоторых настройках, таких как (статические файлы / WhiteNoise) за вас.
import django_heroku
django_heroku.settings(locals())Обновите DEBUG в настройках. Не хотим развертывать в продакшн в режиме отладки.
DEBUG = FalseДобавьте файлы в git с помощью следующей команды.
git init
git add . -A
git commit -m 'first commit'Теперь отправьте наше приложение на Heroku с помощью этой команды.
git push heroku masterПланирование работы
Вы можете запустить задачу вручную из локальной командной строки с помощью heroku run python manage.py scrape, но было бы неприятно каждый день запускать ее вручную.
Давайте автоматизируем это.
Войдите в консоль Heroku и перейдите в раздел "Resources", затем "find more add-ons".
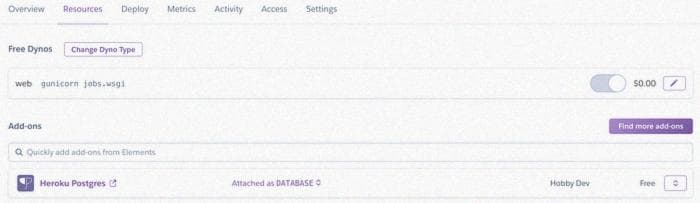
Теперь найдите и нажмите на этот дополнительный модуль. Попробуйте использовать комбинацию клавиш "ctrl+f", чтобы его найти. У Heroku есть огромное количество потенциальных дополнительных модулей. Он выглядит примерно так.

Теперь добавьте его к своему приложению, чтобы у вас было следующее.

Нажмите на него и создайте задачу, everyday at… 12am UTC. Не стоит чаще, чем необходимо, обращаться к веб-сайтам!
Введите свою команду и сохраните ее.
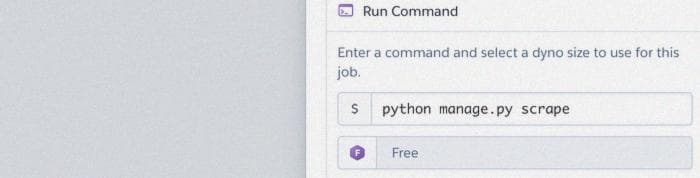
Сохраните и мы закончили!
Теперь просто дождитесь 12 часов UTC (или любого другого времени, которое вы выбрали), и ваша база данных будет заполняться.
Заключение
Мы затронули много вещей здесь. Django, Heroku, планирование, парсинг веб-страниц, Postgres.
Хотя я использовал пример с желанием узнать, когда компания размещает новую вакансию, есть много причин, по которым вы можете захотеть спарсить веб-сайт.
- Компании электронной коммерции хотят отслеживать цены конкурентов.
- Рекрутеры топ-менеджеров могут хотеть видеть, когда компания размещает вакансию.
- Вы или я можем хотеть видеть, когда на Kaggle добавляется новое соревнование.
Этот учебник был просто для иллюстрации того, что возможно. Дайте мне знать, если вы создали что-то интересное с помощью парсинга веб-страниц в комментариях.